V2Meow: Meowing to the Visual Beat via Music Generation
in
Workshop: NeurIPS 2023 Workshop on Machine Learning for Creativity and Design
{kind=link}
Abstract
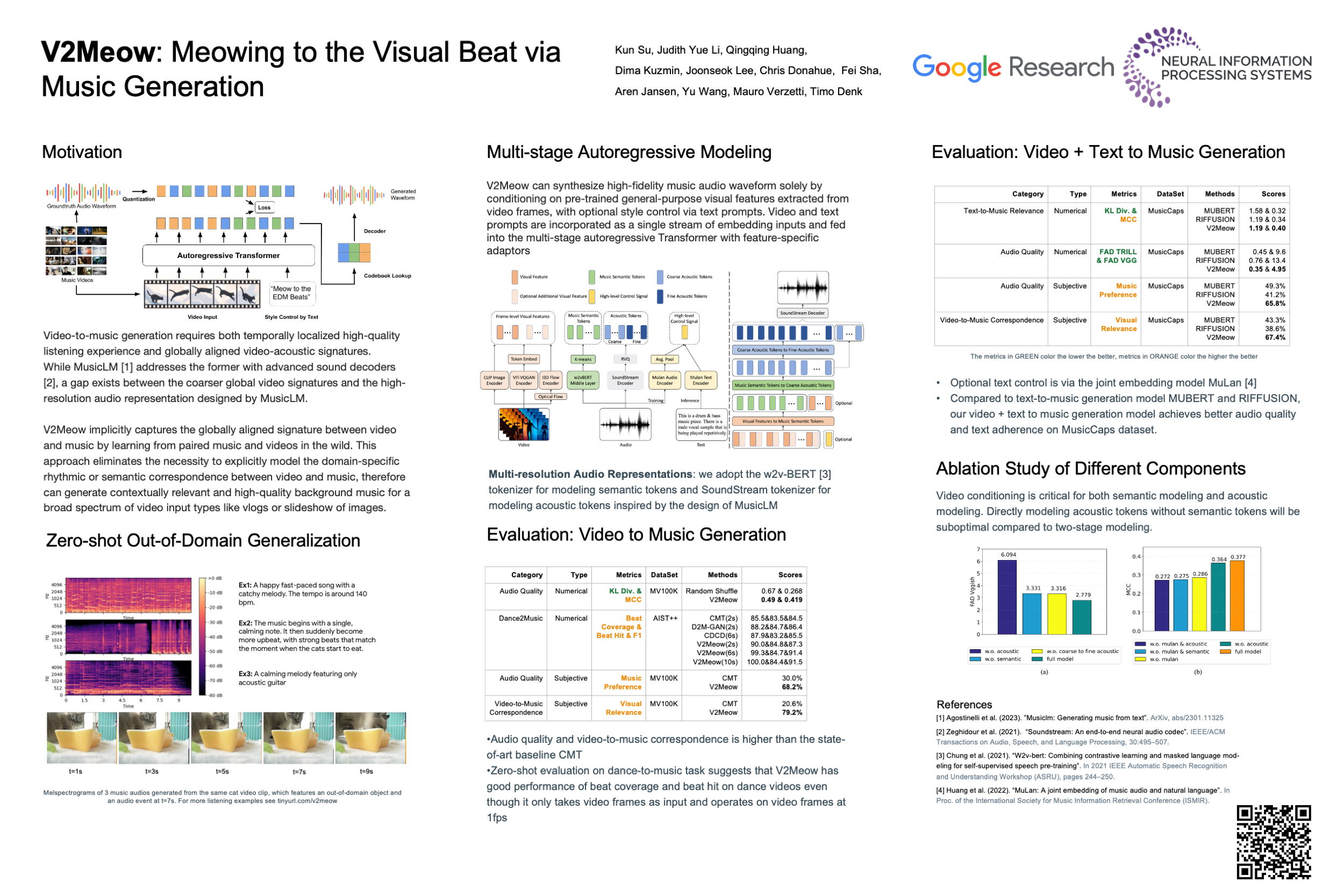
We propose a video-to-music generation system called V2Meow that can generate high-quality music audio for a diverse range of video input types based on a multi-stage autoregressive model, without the need to explicitly model the rhythmic or semantic video-music correspondence. Compared to previous video to music generation work, the video and text prompts are incorporated as a single stream of embedding inputs and fed into the Transformer with feature-specific adaptors. Trained on O(100K) music audio clips paired with video frames mined from in-the-wild music videos, V2Meow is competitive with previous domain-specific models when evaluated in a zero-shot manner. V2Meow can synthesize high-fidelity music audio waveform solely by conditioning on pre-trained general-purpose visual features extracted from video frames, with optional style control via text prompts. Through both qualitative and quantitative evaluations, we verify that our model outperforms various existing music generation systems in terms of visual-audio correspondence and audio quality. We would like to present a demo during the workshop.