The SVHN Dataset Is Deceptive for Probabilistic Generative Models Due to a Distribution Mismatch
{kind=link}
Abstract
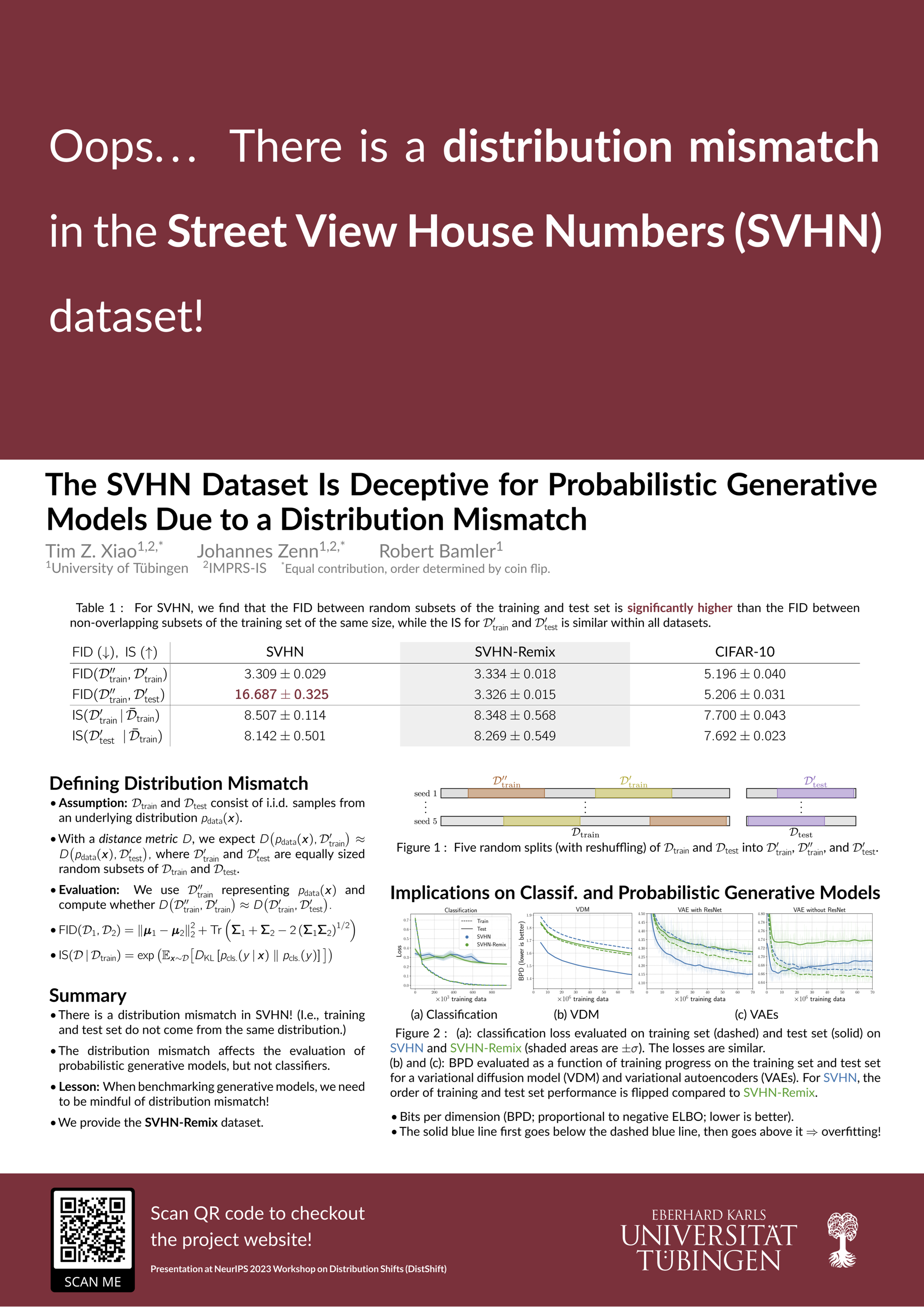
The Street View House Numbers (SVHN) dataset is a popular benchmark dataset in deep learning. Originally designed for digit classification tasks, the SVHN dataset has been widely used as a benchmark for various other tasks including generative modeling. However, with this work, we aim to warn the community about an issue of the SVHN dataset as a benchmark for generative modeling tasks: we discover that the official split into training set and test set of the SVHN dataset are not drawn from the same distribution. We empirically show that this distribution mismatch has little impact on the classification task (which may explain why this issue has not been detected before), but it severely affects the evaluation of probabilistic generative models, such as Variational Autoencoders and diffusion models. As a workaround, we propose to mix and re-split the official training and test set when SVHN is used for tasks other than classification. We publish a new split and the corresponding indices we used to create it.