Efficient and Approximate Per-Example Gradient Norms for Gradient Noise Scale
{kind=link}
Abstract
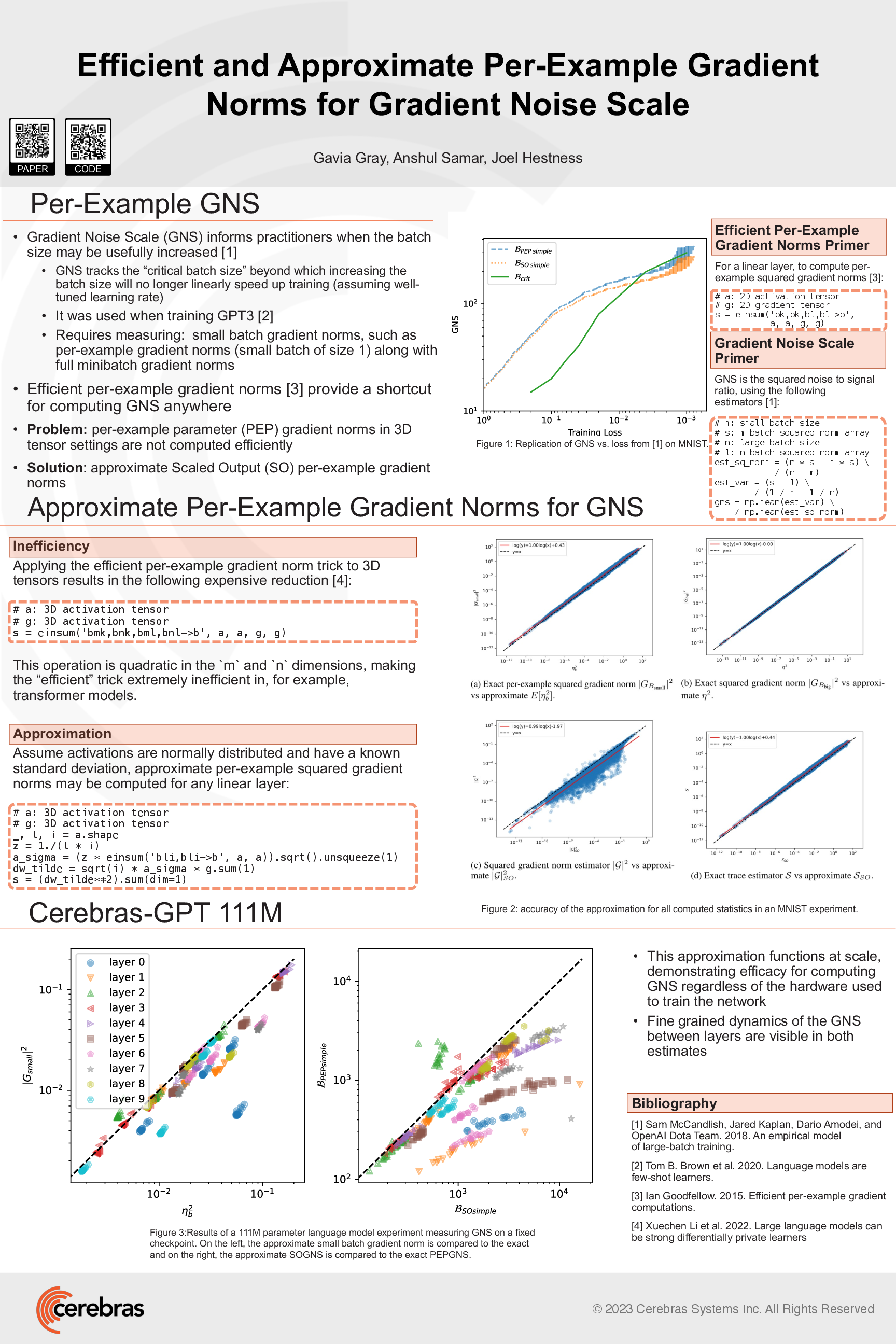
The gradient noise scale is valuable to compute because it provides a suggestion for a compute efficient batch size when training a deep learning model. However, computing it can be awkward or expensive depending on the approach taken due to difficulty obtaining small batch gradient norm estimates. ``Efficient'' per-example gradient norms provide accurate small batch gradient norms but are inefficient in transformer or convolutional models. By assuming activations are normally distributed, we compute an approximate per-example gradient norm that tracks the true per-example gradient norm in practical settings. Using this approximation, we construct a Scaled Output Gradient Noise Scale (SOGNS) that is generally applicable at negligible cost and provides additional feedback to the practitioner during training.