Sparse Backpropagation for MoE Training
in
Workshop: Workshop on Advancing Neural Network Training (WANT): Computational Efficiency, Scalability, and Resource Optimization
{kind=link}
Abstract
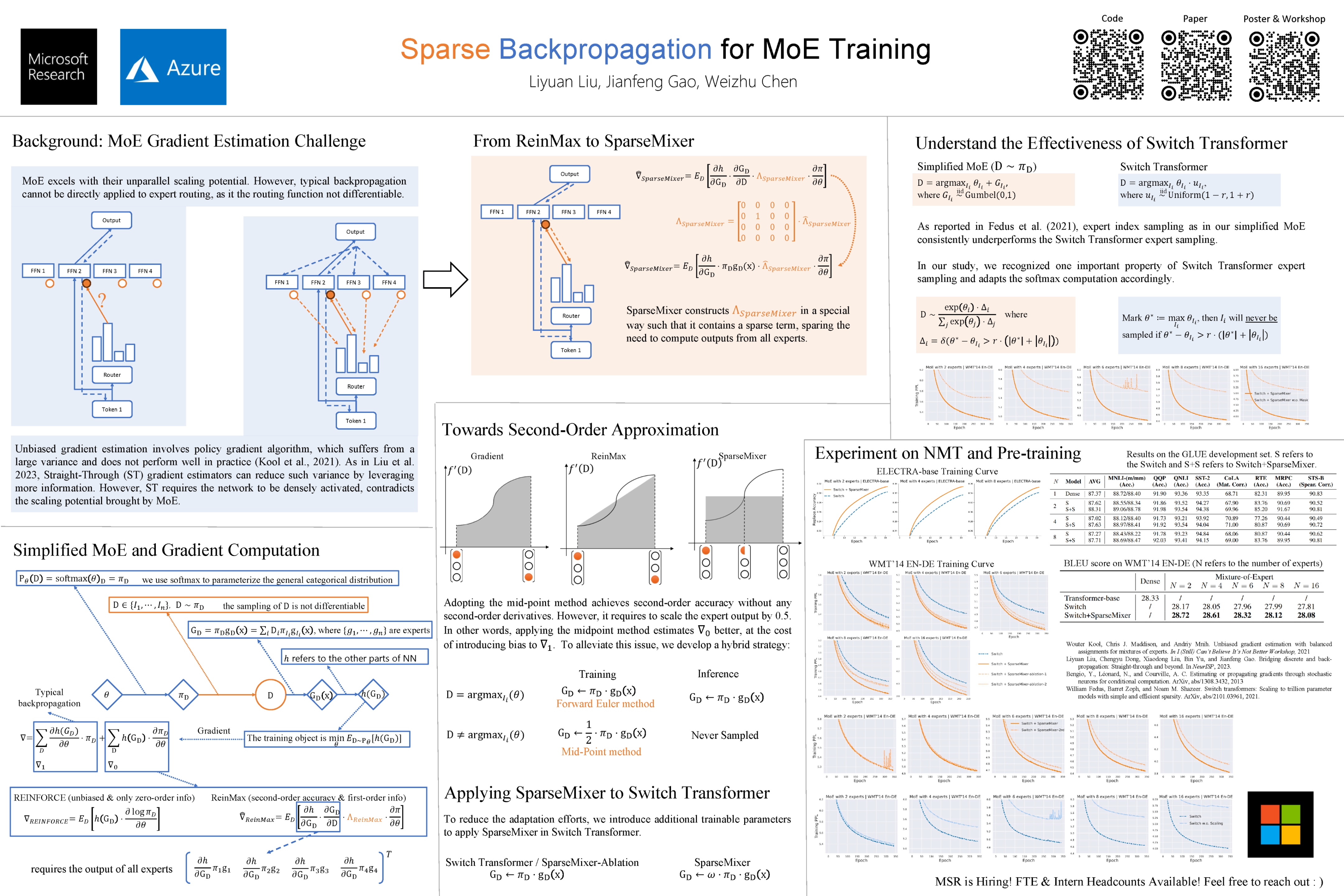
One defining characteristic of Mixture-of-Expert (MoE) models is their capacity for conducting sparse computation via expert routing, leading to remarkable scalability. However, backpropagation, the cornerstone of deep learning, requires dense computation, thereby posting challenges in MoE gradient computations. Here, we introduce SparseMixer, a scalable gradient estimator that bridges the gap between backpropagation and sparse expert routing. Unlike typical MoE training which strategically neglects certain gradient terms for the sake of sparse computation and scalability, SparseMixer provides scalable gradient approximations for these terms, enabling reliable gradient estimation in MoE training. Grounded in a numerical ODE framework, SparseMixer harnesses the mid-point method, a second-order ODE solver, to deliver precise gradient approximations with negligible computational overhead. Applying SparseMixer to Switch Transformer on both pre-training and machine translation tasks, SparseMixer showcases considerable performance gain, accelerating training convergence up to 2 times.