Towards Foundation Models for Scientific Machine Learning: Characterizing Scaling and Transfer Behavior
{kind=link}
Abstract
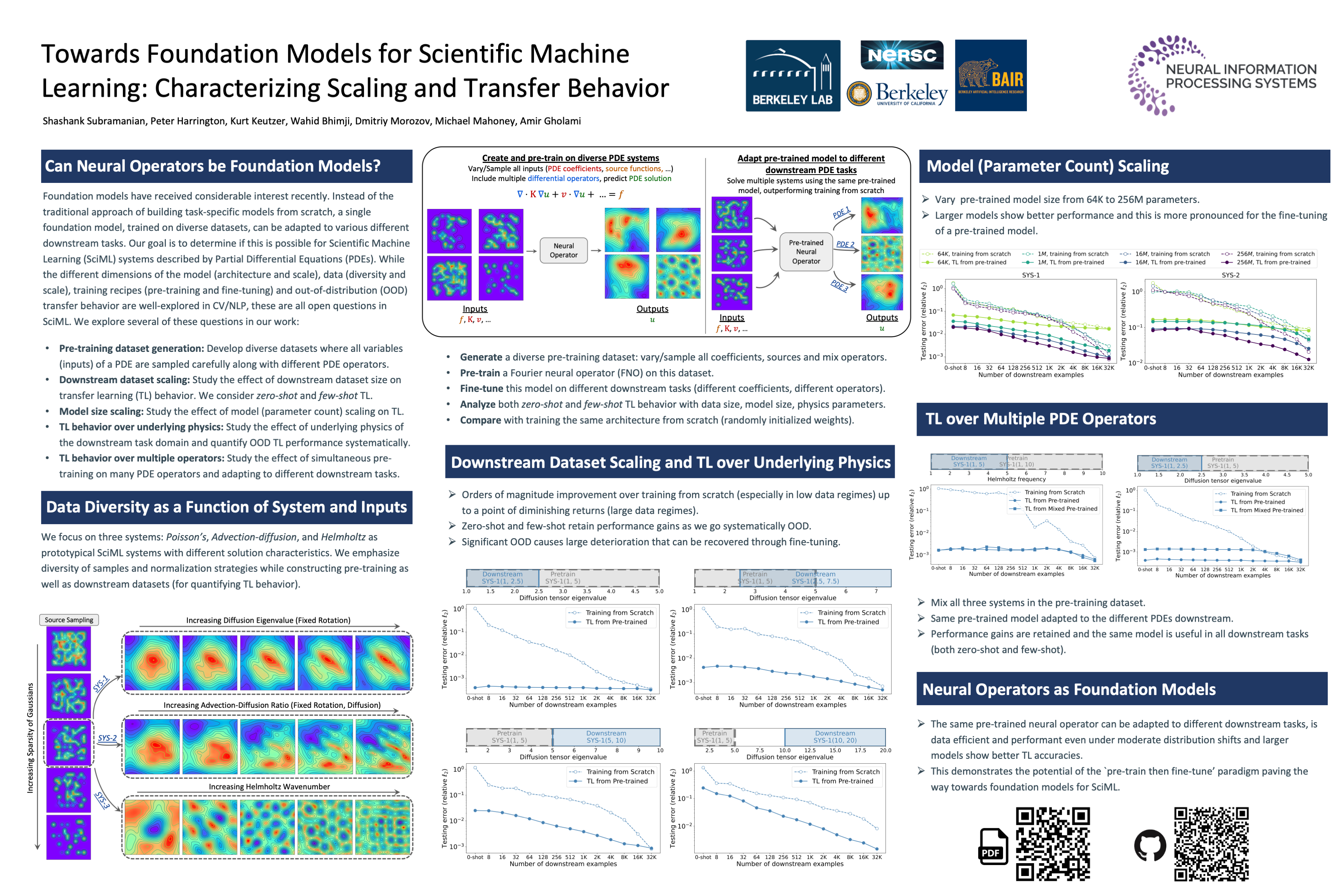
Pre-trained machine learning (ML) models have shown great performance for awide range of applications, in particular in natural language processing (NLP)and computer vision (CV). Here, we study how pre-training could be used forscientific machine learning (SciML) applications, specifically in the context oftransfer learning. We study the transfer behavior of these models as (i) the pretrainedmodel size is scaled, (ii) the downstream training dataset size is scaled,(iii) the physics parameters are systematically pushed out of distribution, and (iv)how a single model pre-trained on a mixture of different physics problems canbe adapted to various downstream applications. We find that—when fine-tunedappropriately—transfer learning can help reach desired accuracy levels with ordersof magnitude fewer downstream examples (across different tasks that can even beout-of-distribution) than training from scratch, with consistent behaviour across awide range of downstream examples. We also find that fine-tuning these modelsyields more performance gains as model size increases, compared to training fromscratch on new downstream tasks. These results hold for a broad range of PDElearning tasks. All in all, our results demonstrate the potential of the “pre-train andfine-tune” paradigm for SciML problems, demonstrating a path towards buildingSciML foundation models. Our code is available as open-source.