What’s Left? Concept Grounding with Logic-Enhanced Foundation Models
{kind=link}
Abstract
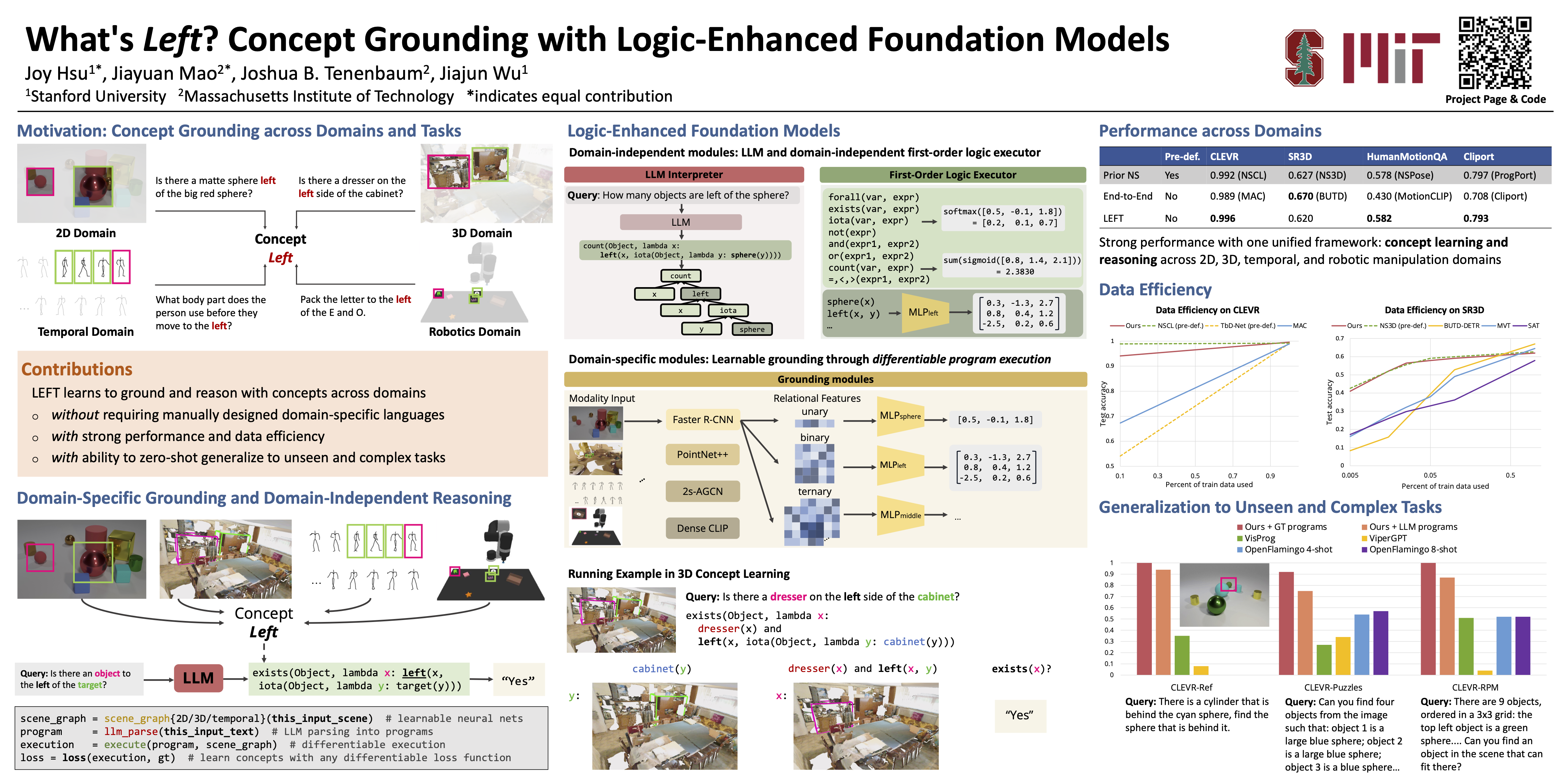
Recent works such as VisProg and ViperGPT have smartly composed foundation models for visual reasoning—using large language models (LLMs) to produce programs that can be executed by pre-trained vision-language models. However, they operate in limited domains, such as 2D images, not fully exploiting the generalization of language: abstract concepts like “left” can also be grounded in 3D, temporal, and action data, as in moving to your left. This limited generalization stems from these inference-only methods’ inability to learn or adapt pre-trained models to a new domain. We propose the Logic-Enhanced FoundaTion Model (LEFT), a unified framework that learns to ground and reason with concepts across domains with a differentiable, domain-independent, first-order logic-based program executor. LEFT has an LLM interpreter that outputs a program represented in a general, logic-based reasoning language, which is shared across all domains and tasks. LEFT’s executor then executes the program with trainable domain-specific grounding modules. We show that LEFT flexibly learns concepts in four domains: 2D images, 3D scenes, human motions, and robotic manipulation. It exhibits strong reasoning ability in a wide variety of tasks, including those that are complex and not seen during training, and can be easily applied to new domains.