Survival Instinct in Offline Reinforcement Learning
{kind=link}
Abstract
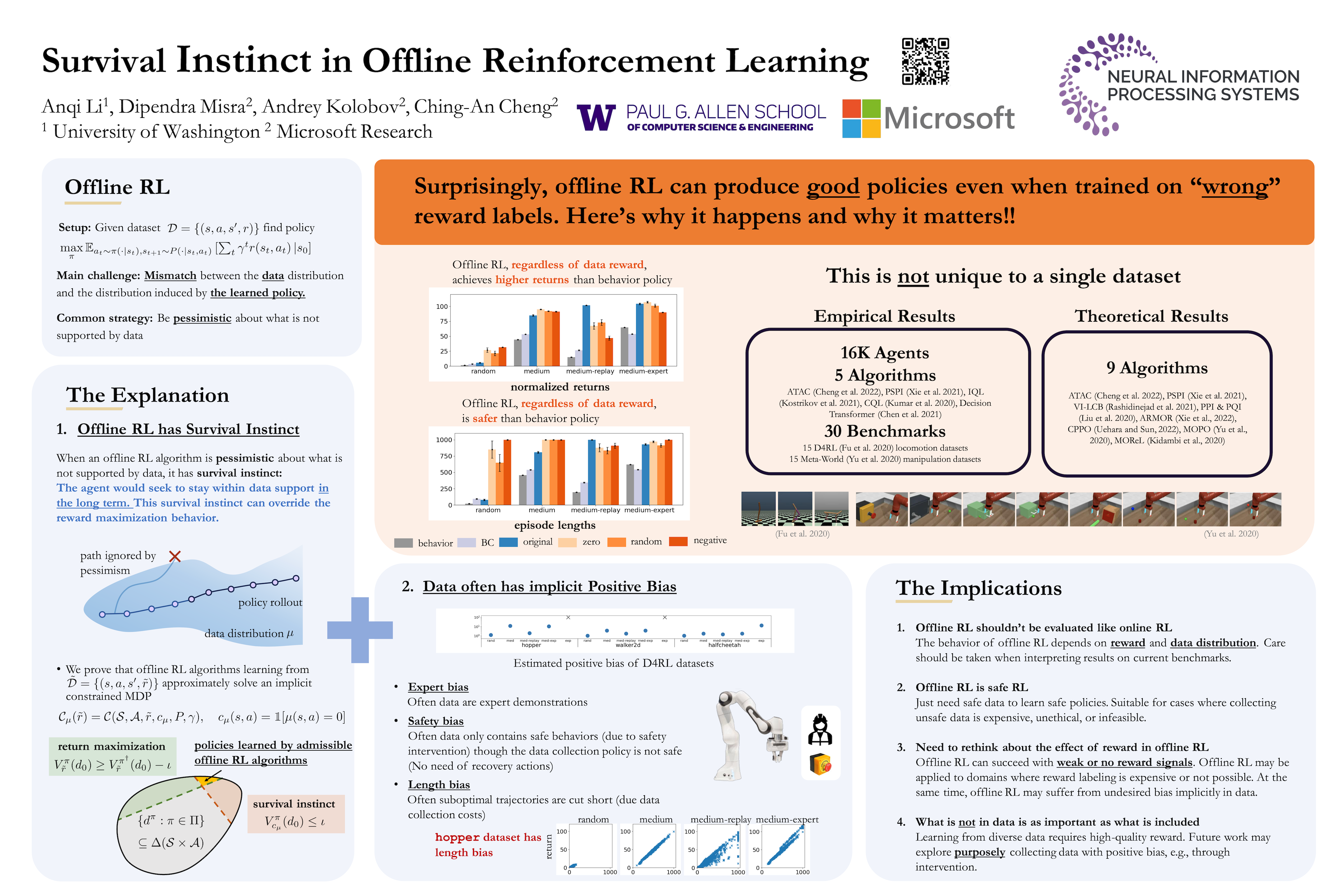
We present a novel observation about the behavior of offline reinforcement learning (RL) algorithms: on many benchmark datasets, offline RL can produce well-performing and safe policies even when trained with "wrong" reward labels, such as those that are zero everywhere or are negatives of the true rewards. This phenomenon cannot be easily explained by offline RL's return maximization objective. Moreover, it gives offline RL a degree of robustness that is uncharacteristic of its online RL counterparts, which are known to be sensitive to reward design. We demonstrate that this surprising robustness property is attributable to an interplay between the notion of pessimism in offline RL algorithms and certain implicit biases in common data collection practices. As we prove in this work, pessimism endows the agent with a survival instinct, i.e., an incentive to stay within the data support in the long term, while the limited and biased data coverage further constrains the set of survival policies. Formally, given a reward class -- which may not even contain the true reward -- we identify conditions on the training data distribution that enable offline RL to learn a near-optimal and safe policy from any reward within the class. We argue that the survival instinct should be taken into account when interpreting results from existing offline RL benchmarks and when creating future ones. Our empirical and theoretical results suggest a new paradigm for offline RL, whereby an agent is "nudged" to learn a desirable behavior with imperfect reward but purposely biased data coverage. Please visit our website https://survival-instinct.github.io for accompanied code and videos.