Adversarial Counterfactual Environment Model Learning
{kind=link}
Abstract
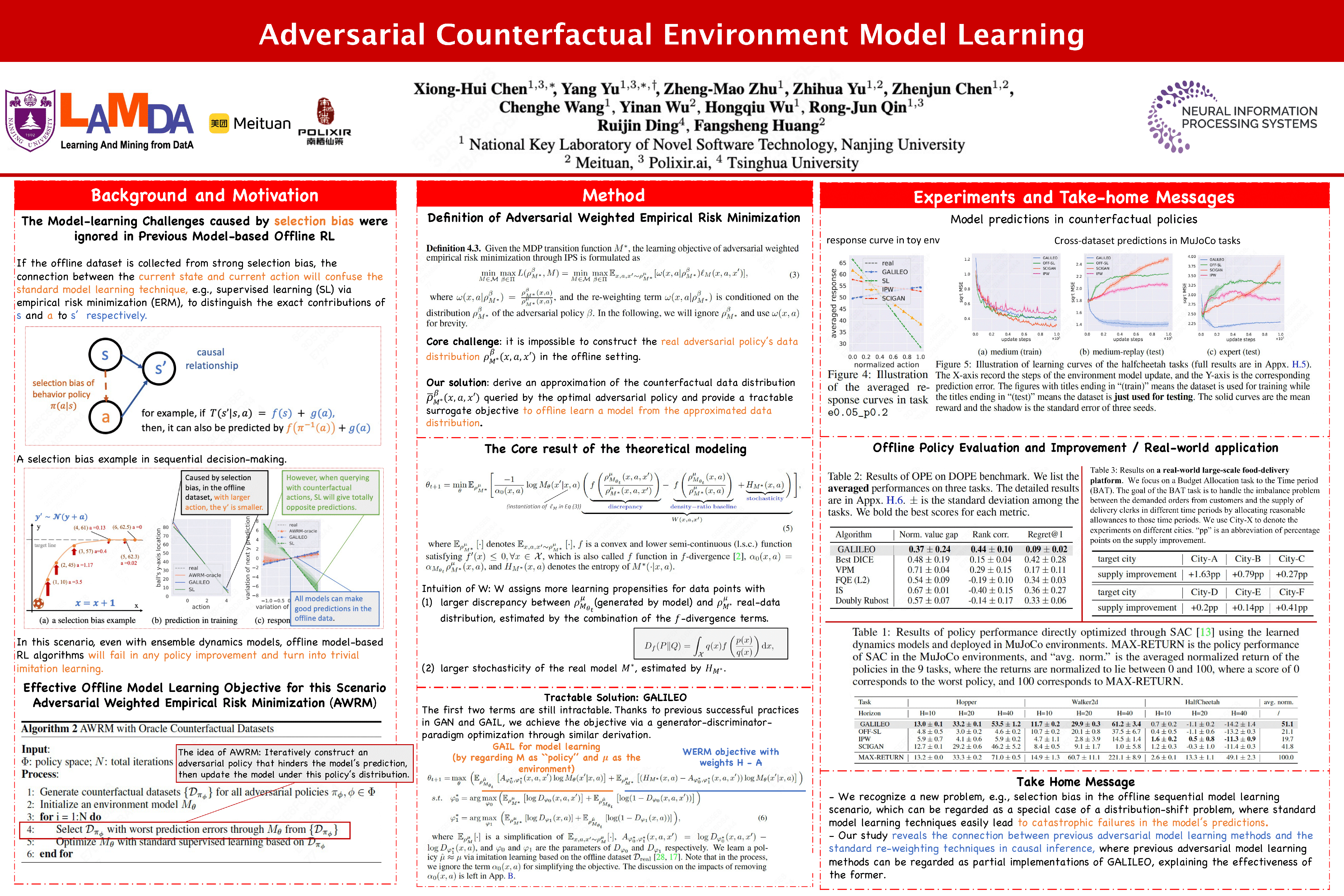
An accurate environment dynamics model is crucial for various downstream tasks in sequential decision-making, such as counterfactual prediction, off-policy evaluation, and offline reinforcement learning. Currently, these models were learned through empirical risk minimization (ERM) by step-wise fitting of historical transition data. This way was previously believed unreliable over long-horizon rollouts because of the compounding errors, which can lead to uncontrollable inaccuracies in predictions. In this paper, we find that the challenge extends beyond just long-term prediction errors: we reveal that even when planning with one step, learned dynamics models can also perform poorly due to the selection bias of behavior policies during data collection. This issue will significantly mislead the policy optimization process even in identifying single-step optimal actions, further leading to a greater risk in sequential decision-making scenarios.To tackle this problem, we introduce a novel model-learning objective called adversarial weighted empirical risk minimization (AWRM). AWRM incorporates an adversarial policy that exploits the model to generate a data distribution that weakens the model's prediction accuracy, and subsequently, the model is learned under this adversarial data distribution.We implement a practical algorithm, GALILEO, for AWRM and evaluate it on two synthetic tasks, three continuous-control tasks, and \textit{a real-world application}. The experiments demonstrate that GALILEO can accurately predict counterfactual actions and improve various downstream tasks, including offline policy evaluation and improvement, as well as online decision-making.