Learning to Group Auxiliary Datasets for Molecule
{kind=link}
Abstract
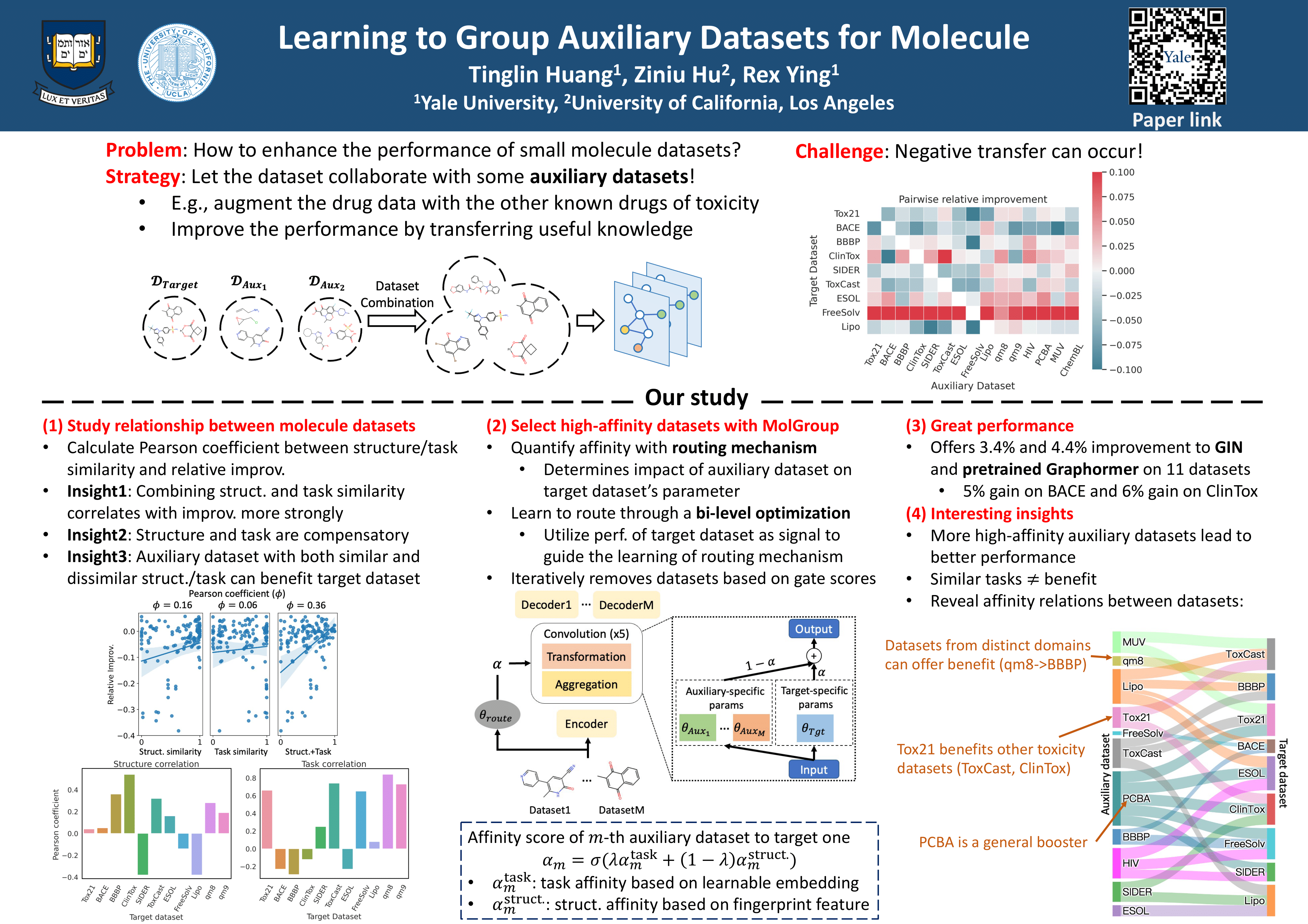
The limited availability of annotations in small molecule datasets presents a challenge to machine learning models. To address this, one common strategy is to collaborate with additional auxiliary datasets. However, having more data does not always guarantee improvements. Negative transfer can occur when the knowledge in the target dataset differs or contradicts that of the auxiliary molecule datasets. In light of this, identifying the auxiliary molecule datasets that can benefit the target dataset when jointly trained remains a critical and unresolved problem. Through an empirical analysis, we observe that combining graph structure similarity and task similarity can serve as a more reliable indicator for identifying high-affinity auxiliary datasets. Motivated by this insight, we propose MolGroup, which separates the dataset affinity into task and structure affinity to predict the potential benefits of each auxiliary molecule dataset. MolGroup achieves this by utilizing a routing mechanism optimized through a bi-level optimization framework. Empowered by the meta gradient, the routing mechanism is optimized toward maximizing the target dataset's performance and quantifies the affinity as the gating score. As a result, MolGroup is capable of predicting the optimal combination of auxiliary datasets for each target dataset. Our extensive experiments demonstrate the efficiency and effectiveness of MolGroup, showing an average improvement of 4.41%/3.47% for GIN/Graphormer trained with the group of molecule datasets selected by MolGroup on 11 target molecule datasets.