Convolutional Visual Prompt for Robust Visual Perception
{kind=link}
Abstract
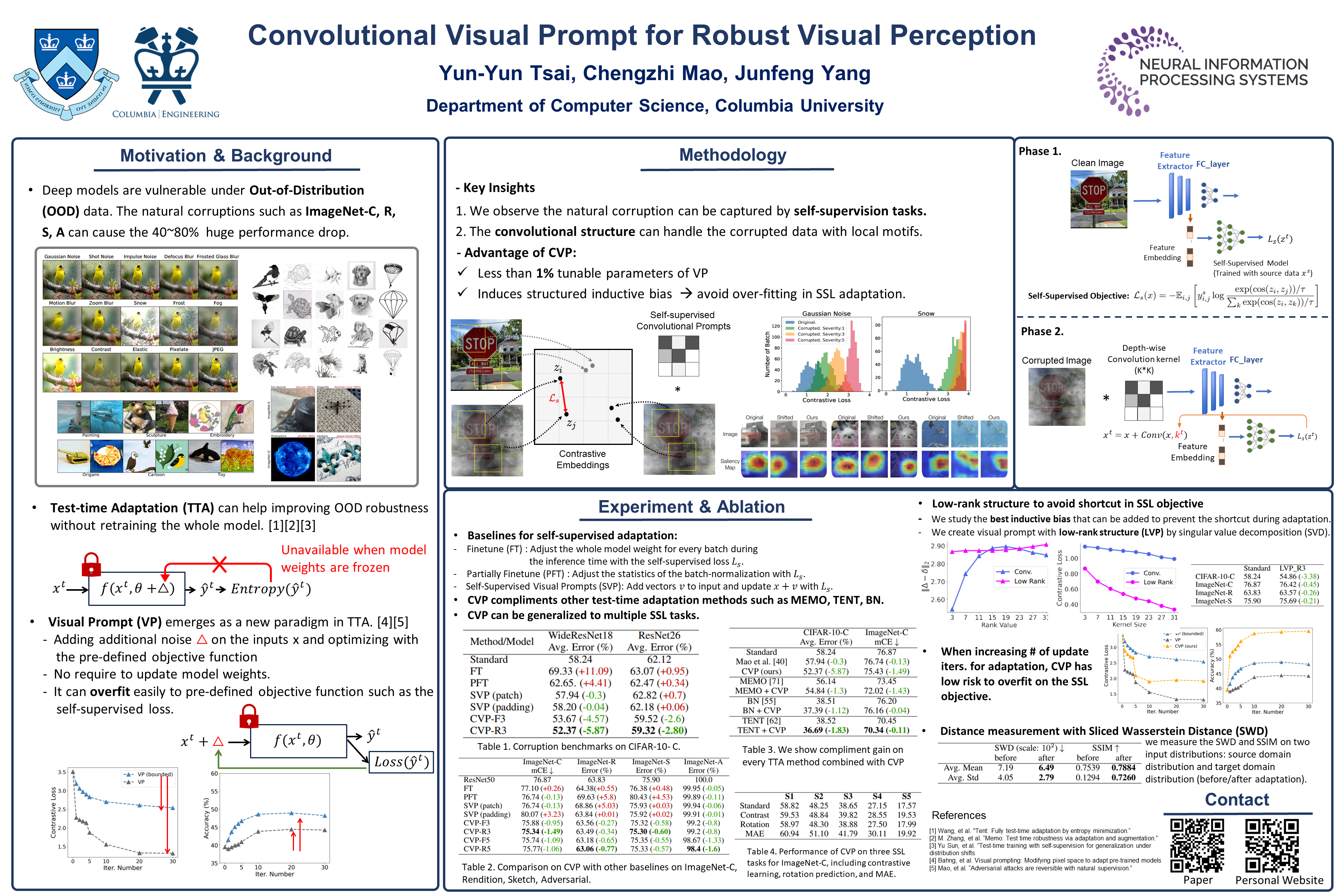
Vision models are often vulnerable to out-of-distribution (OOD) samples without adapting. While visual prompts offer a lightweight method of input-space adaptation for large-scale vision models, they rely on a high-dimensional additive vector and labeled data. This leads to overfitting when adapting models in a self-supervised test-time setting without labels. We introduce convolutional visual prompts (CVP) for label-free test-time adaptation for robust visual perception. The structured nature of CVP demands fewer trainable parameters, less than 1\% compared to standard visual prompts, combating overfitting. Extensive experiments and analysis on a wide variety of OOD visual perception tasks show that our approach is effective, improving robustness by up to 5.87\% over several large-scale models.