Learning Topology-Agnostic EEG Representations with Geometry-Aware Modeling
{kind=link}
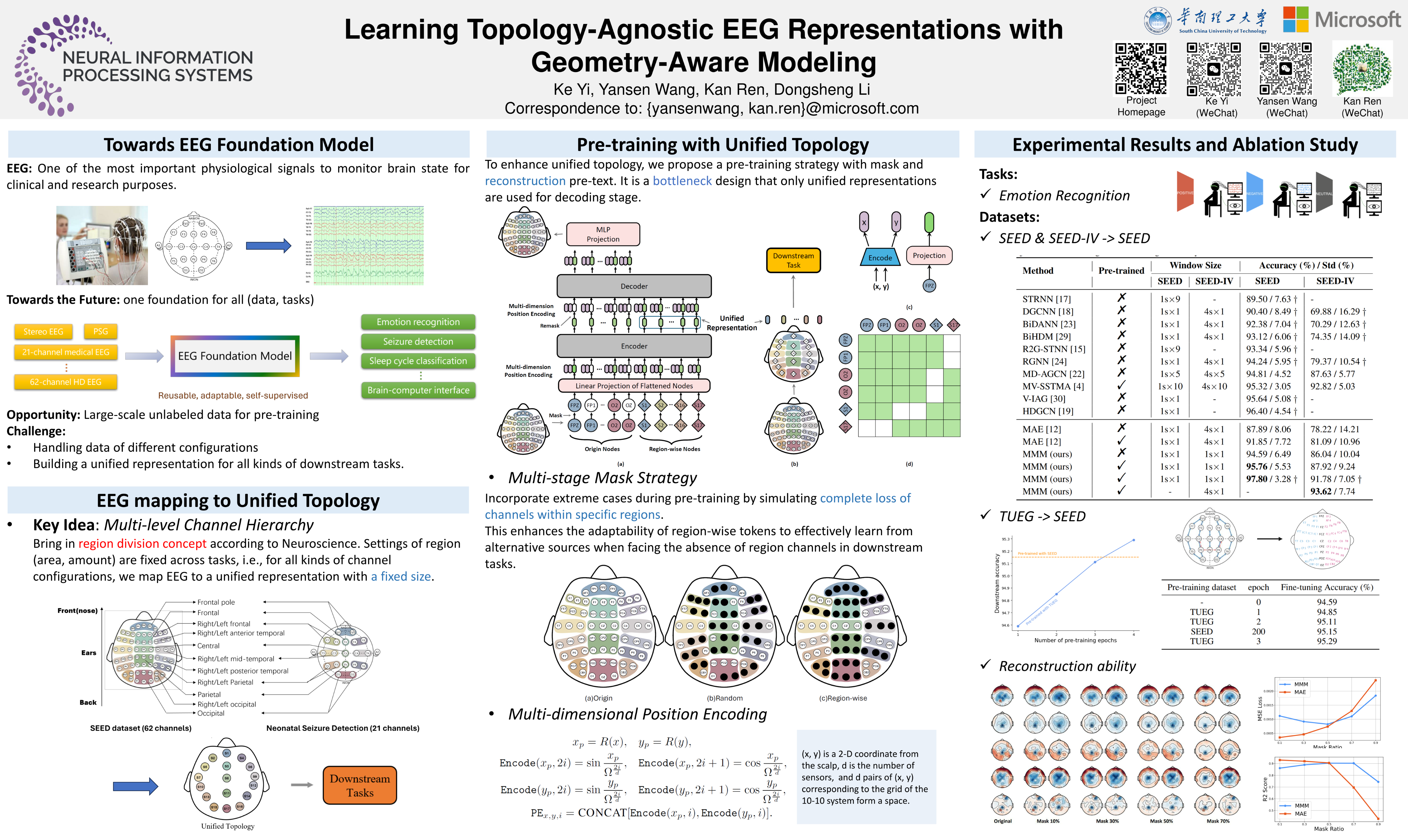
Abstract
Large-scale pre-training has shown great potential to enhance models on downstream tasks in vision and language. Developing similar techniques for scalp electroencephalogram (EEG) is suitable since unlabelled data is plentiful. Meanwhile, various sampling channel selections and inherent structural and spatial information bring challenges and avenues to improve existing pre-training strategies further. In order to break boundaries between different EEG resources and facilitate cross-dataset EEG pre-training, we propose to map all kinds of channel selections to a unified topology. We further introduce MMM, a pre-training framework with Multi-dimensional position encoding, Multi-level channel hierarchy, and Multi-stage pre-training strategy built on the unified topology to obtain topology-agnostic representations. Experiments demonstrate that our approach yields impressive improvements over previous state-of-the-art techniques on emotional recognition benchmark datasets.