Taylor TD-learning
{kind=link}
Abstract
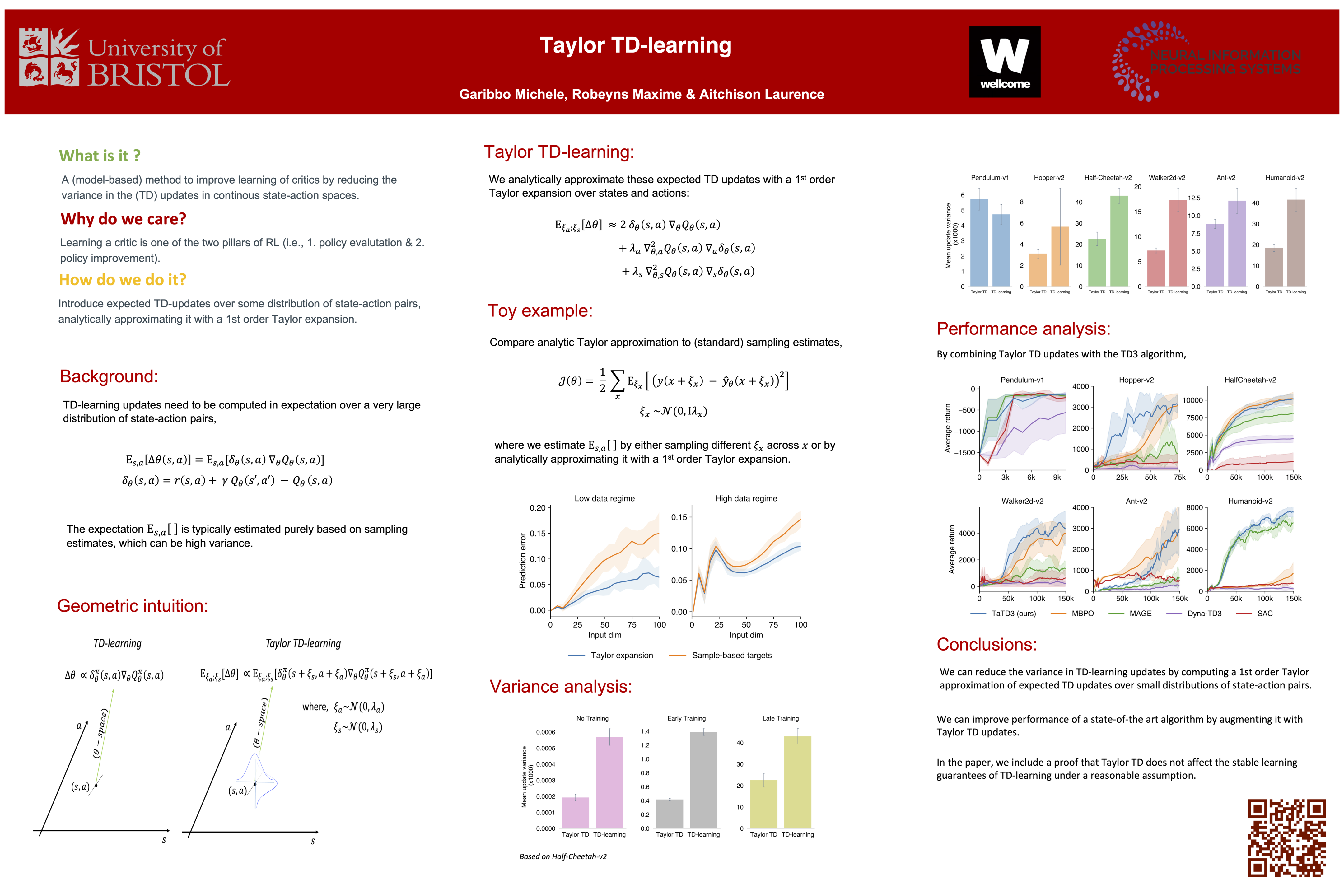
Many reinforcement learning approaches rely on temporal-difference (TD) learning to learn a critic.However, TD-learning updates can be high variance.Here, we introduce a model-based RL framework, Taylor TD, which reduces this variance in continuous state-action settings. Taylor TD uses a first-order Taylor series expansion of TD updates.This expansion allows Taylor TD to analytically integrate over stochasticity in the action-choice, and some stochasticity in the state distribution for the initial state and action of each TD update.We include theoretical and empirical evidence that Taylor TD updates are indeed lower variance than standard TD updates. Additionally, we show Taylor TD has the same stable learning guarantees as standard TD-learning with linear function approximation under a reasonable assumption.Next, we combine Taylor TD with the TD3 algorithm, forming TaTD3.We show TaTD3 performs as well, if not better, than several state-of-the art model-free and model-based baseline algorithms on a set of standard benchmark tasks.