Learning Modulated Transformation in GANs
{kind=link}
Abstract
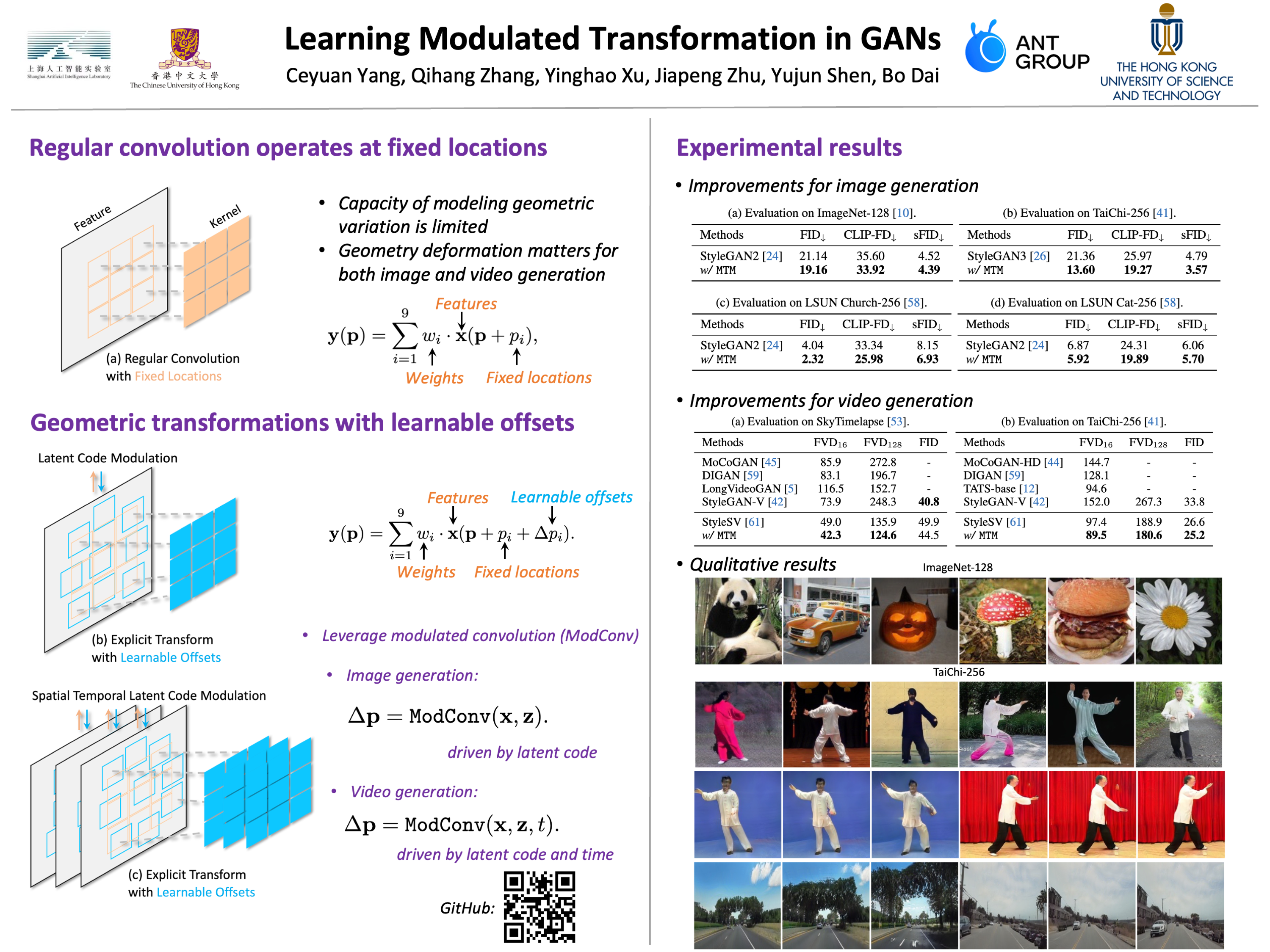
The success of style-based generators largely benefits from style modulation,which helps take care of the cross-instance variation within data. However, theinstance-wise stochasticity is typically introduced via regular convolution, wherekernels interact with features at some fixed locations, limiting its capacity formodeling geometric variation. To alleviate this problem, we equip the generatorin generative adversarial networks (GANs) with a plug-and-play module, termedas modulated transformation module (MTM). This module predicts spatial offsetsunder the control of latent codes, based on which the convolution operation canbe applied at variable locations for different instances, and hence offers the modelan additional degree of freedom to handle geometry deformation. Extensiveexperiments suggest that our approach can be faithfully generalized to variousgenerative tasks, including image generation, 3D-aware image synthesis, andvideo generation, and get compatible with state-of-the-art frameworks withoutany hyper-parameter tuning. It is noteworthy that, towards human generation onthe challenging TaiChi dataset, we improve the FID of StyleGAN3 from 21.36 to13.60, demonstrating the efficacy of learning modulated geometry transformation.Code and models are available at https://github.com/limbo0000/mtm.