Coop: Memory is not a Commodity
Jianhao Zhang ⋅ Shihan Ma ⋅ Peihong Liu ⋅ Jinhui Yuan
2023 Spotlight Poster
{kind=link}
Abstract
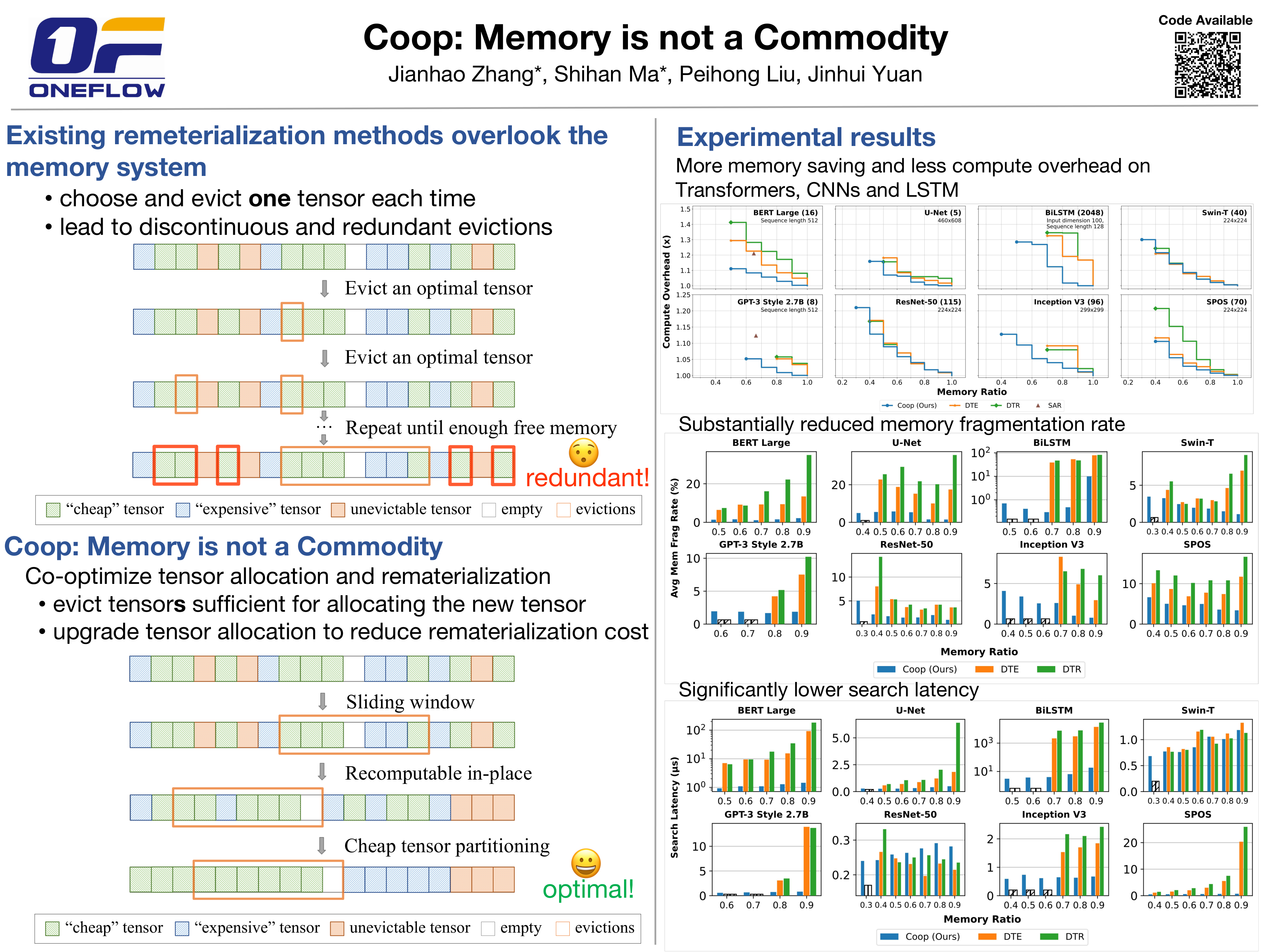
Tensor rematerialization allows the training of deep neural networks (DNNs) under limited memory budgets by checkpointing the models and recomputing the evicted tensors as needed. However, the existing tensor rematerialization techniques overlook the memory system in deep learning frameworks and implicitly assume that free memory blocks at different addresses are identical. Under this flawed assumption, discontiguous tensors are evicted, among which some are not used to allocate the new tensor. This leads to severe memory fragmentation and increases the cost of potential rematerializations.To address this issue, we propose to evict tensors within a sliding window to ensure all evictions are contiguous and are immediately used. Furthermore, we proposed cheap tensor partitioning and recomputable in-place to further reduce the rematerialization cost by optimizing the tensor allocation.We named our method Coop as it is a co-optimization of tensor allocation and tensor rematerialization. We evaluated Coop on eight representative DNNs. The experimental results demonstrate that Coop achieves up to $2\times$ memory saving and hugely reduces compute overhead, search latency, and memory fragmentation compared to the state-of-the-art baselines.
Video
Chat is not available.
Successful Page Load