Are Diffusion Models Vision-And-Language Reasoners?
{kind=link}
Abstract
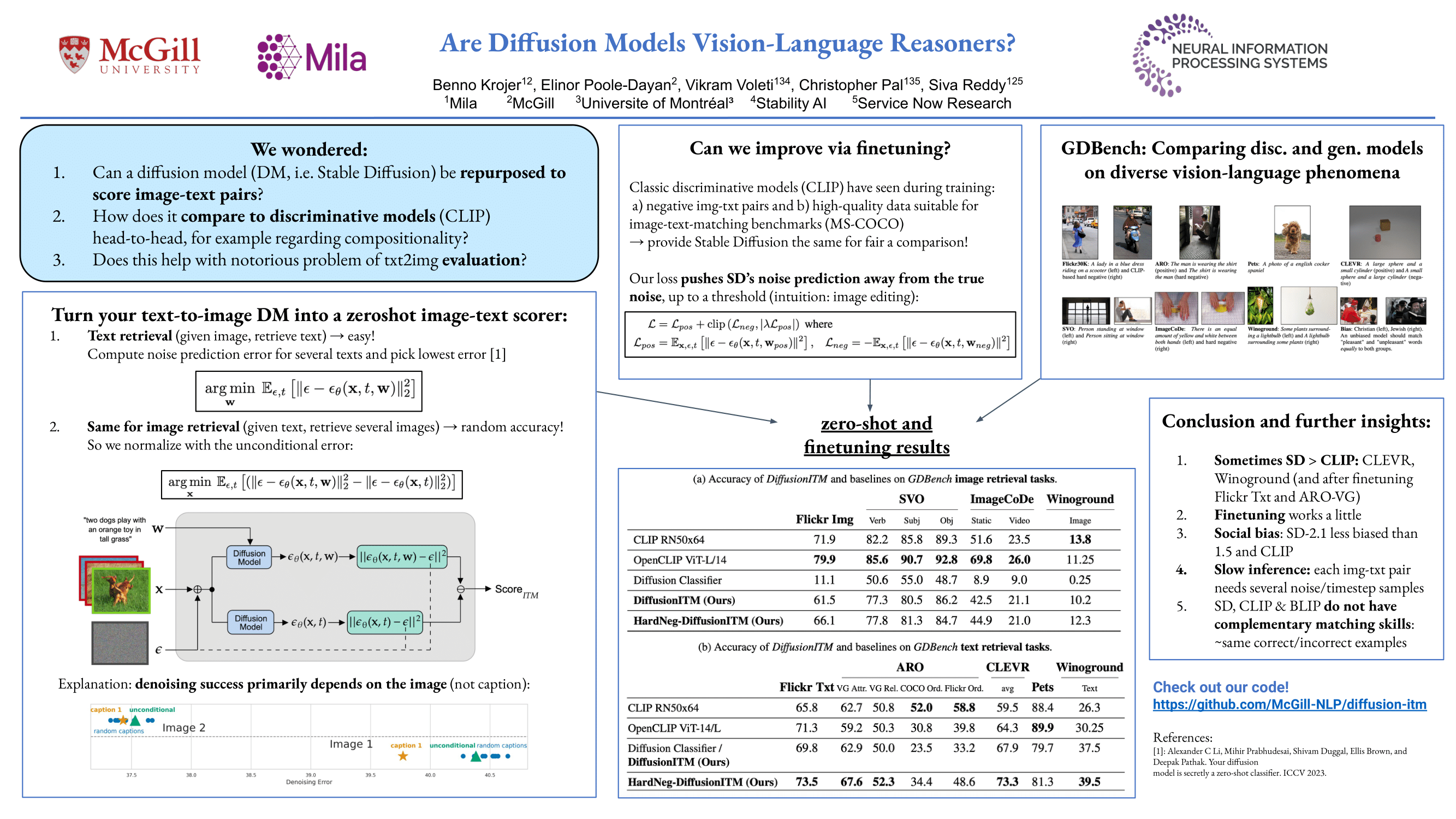
Text-conditioned image generation models have recently shown immense qualitative success using denoising diffusion processes. However, unlike discriminative vision-and-language models, it is a non-trivial task to subject these diffusion-based generative models to automatic fine-grained quantitative evaluation of high-level phenomena such as compositionality.Towards this goal, we perform two innovations. First, we transform diffusion-based models (in our case, Stable Diffusion) for any image-text matching (ITM) task using a novel method called DiffusionITM.Second, we introduce the Generative-Discriminative Evaluation Benchmark (GDBench) benchmark with 7 complex vision-and-language tasks, bias evaluation and detailed analysis.We find that Stable Diffusion + DiffusionITM is competitive on many tasks and outperforms CLIP on compositional tasks like like CLEVR and Winoground.We further boost its compositional performance with a transfer setup by fine-tuning on MS-COCO while retaining generative capabilities. We also measure the stereotypical bias in diffusion models, and find that Stable Diffusion 2.1 is, for the most part, less biased than Stable Diffusion 1.5.Overall, our results point in an exciting direction bringing discriminative and generative model evaluation closer. We will release code and benchmark setup soon.