CLadder: Assessing Causal Reasoning in Language Models
{kind=link}
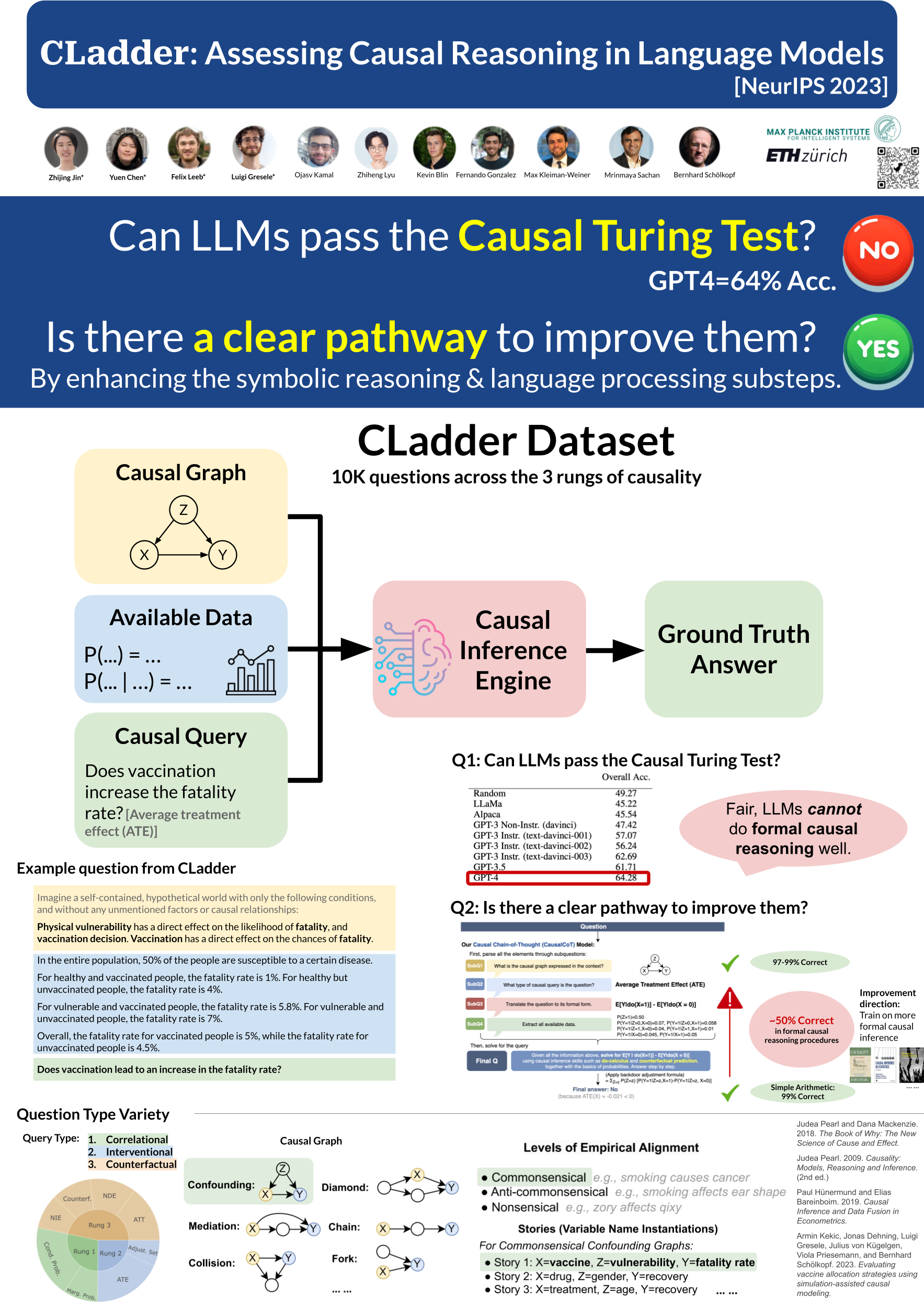
Abstract
The ability to perform causal reasoning is widely considered a core feature of intelligence. In this work, we investigate whether large language models (LLMs) can coherently reason about causality. Much of the existing work in natural language processing (NLP) focuses on evaluating commonsense causal reasoning in LLMs, thus failing to assess whether a model can perform causal inference in accordance with a set of well-defined formal rules. To address this, we propose a new NLP task, causal inference in natural language, inspired by the "causal inference engine" postulated by Judea Pearl et al. We compose a large dataset, CLadder, with 10K samples: based on a collection of causal graphs and queries (associational, interventional, and counterfactual), we obtain symbolic questions and ground-truth answers, through an oracle causal inference engine. These are then translated into natural language. We evaluate multiple LLMs on our dataset, and we introduce and evaluate a bespoke chain-of-thought prompting strategy, CausalCoT. We show that our task is highly challenging for LLMs, and we conduct an in-depth analysis to gain deeper insight into the causal reasoning abilities of LLMs. Our data is open-sourced at https://huggingface.co/datasets/causalNLP/cladder, and our code can be found at https://github.com/causalNLP/cladder.