Diversifying Spatial-Temporal Perception for Video Domain Generalization
{kind=link}
Abstract
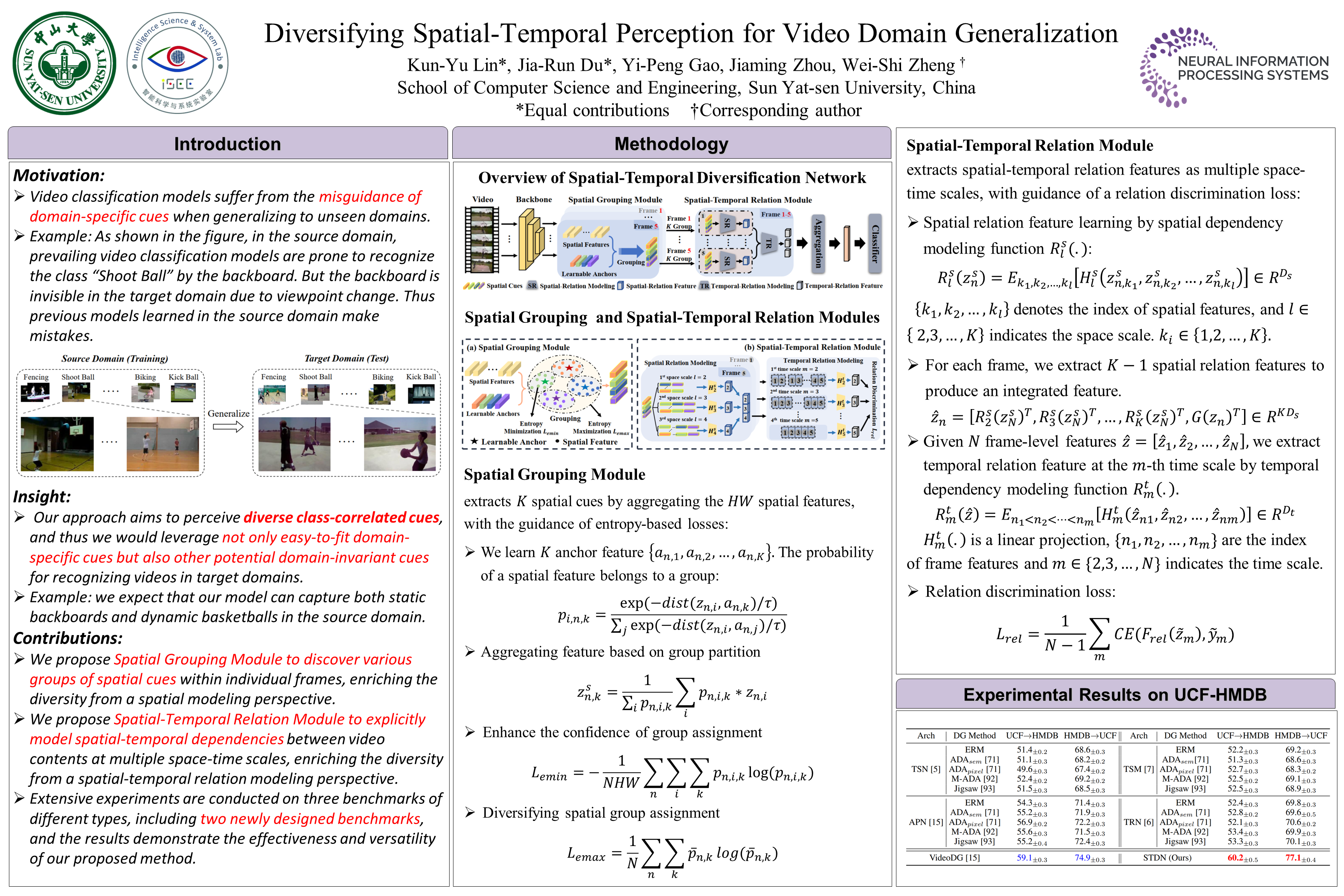
Video domain generalization aims to learn generalizable video classification models for unseen target domains by training in a source domain.A critical challenge of video domain generalization is to defend against the heavy reliance on domain-specific cues extracted from the source domain when recognizing target videos. To this end, we propose to perceive diverse spatial-temporal cues in videos, aiming to discover potential domain-invariant cues in addition to domain-specific cues. We contribute a novel model named Spatial-Temporal Diversification Network (STDN), which improves the diversity from both space and time dimensions of video data. First, our STDN proposes to discover various types of spatial cues within individual frames by spatial grouping. Then, our STDN proposes to explicitly model spatial-temporal dependencies between video contents at multiple space-time scales by spatial-temporal relation modeling. Extensive experiments on three benchmarks of different types demonstrate the effectiveness and versatility of our approach.