Finding Counterfactually Optimal Action Sequences in Continuous State Spaces
{kind=link}
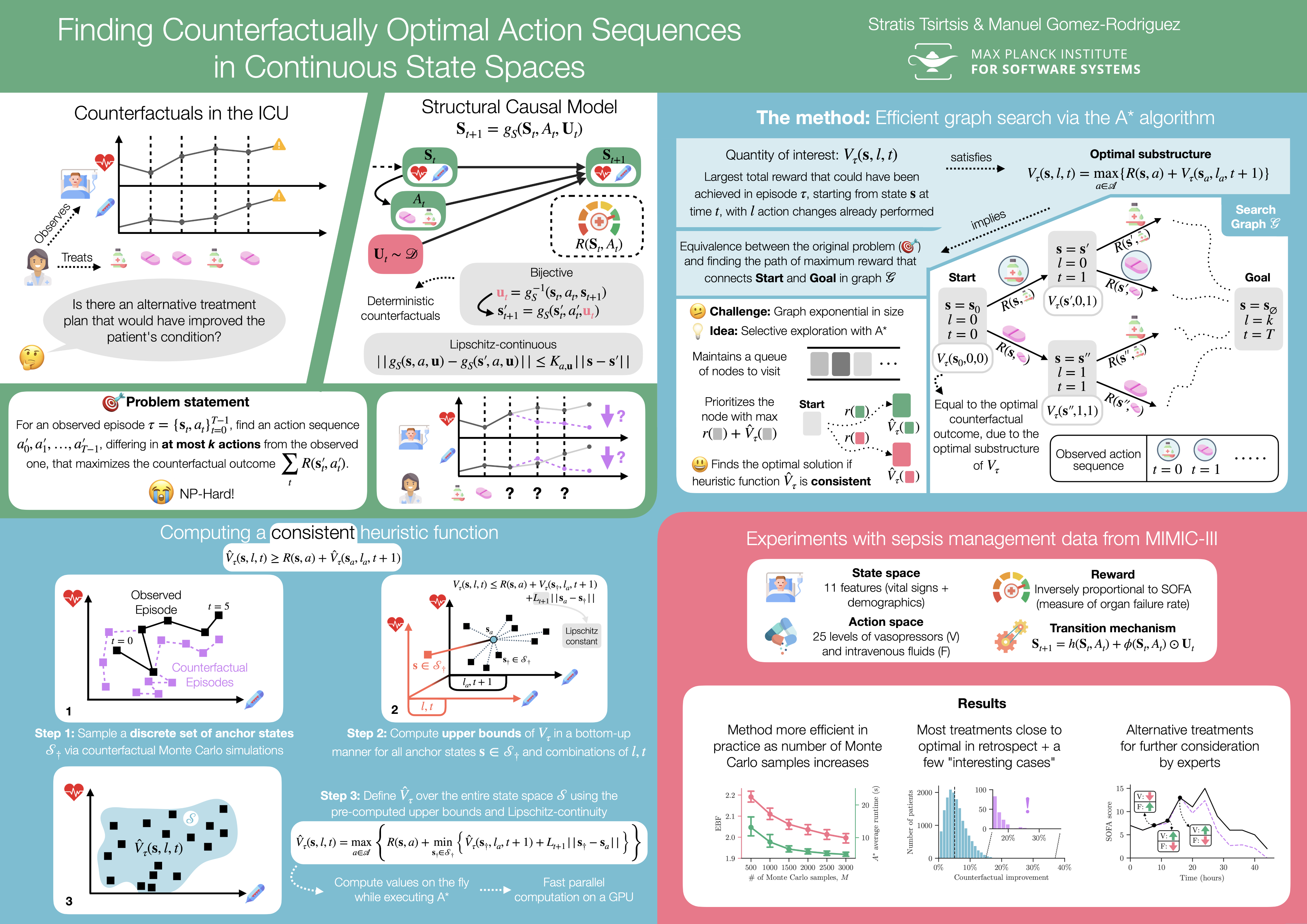
Abstract
Whenever a clinician reflects on the efficacy of a sequence of treatment decisions for a patient, they may try to identify critical time steps where, had they made different decisions, the patient's health would have improved. While recent methods at the intersection of causal inference and reinforcement learning promise to aid human experts, as the clinician above, to retrospectively analyze sequential decision making processes, they have focused on environments with finitely many discrete states. However, in many practical applications, the state of the environment is inherently continuous in nature. In this paper, we aim to fill this gap. We start by formally characterizing a sequence of discrete actions and continuous states using finite horizon Markov decision processes and a broad class of bijective structural causal models. Building upon this characterization, we formalize the problem of finding counterfactually optimal action sequences and show that, in general, we cannot expect to solve it in polynomial time. Then, we develop a search method based on the A* algorithm that, under a natural form of Lipschitz continuity of the environment’s dynamics, is guaranteed to return the optimal solution to the problem. Experiments on real clinical data show that our method is very efficient in practice, and it has the potential to offer interesting insights for sequential decision making tasks.