CAP: Correlation-Aware Pruning for Highly-Accurate Sparse Vision Models
Denis Kuznedelev ⋅ Eldar Kurtić ⋅ Elias Frantar ⋅ Dan Alistarh ⋅ Dan Alistarh
2023 Poster
{kind=link}
Abstract
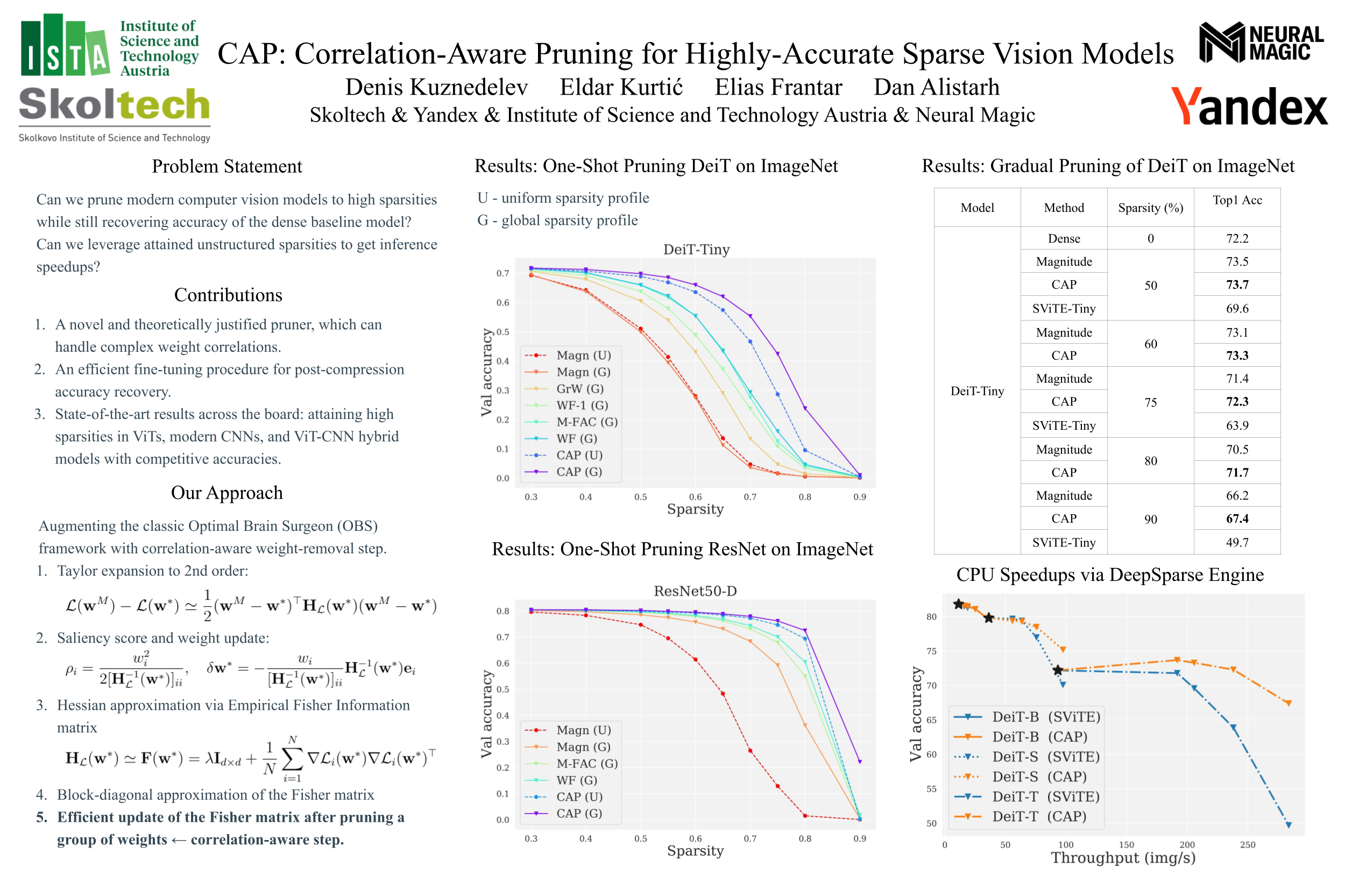
Driven by significant improvements in architectural design and training pipelines, computer visionhas recently experienced dramatic progress in terms of accuracy on classic benchmarks such as ImageNet. These highly-accurate models are challenging to deploy, as they appear harder to compress using standard techniques such as pruning. We address this issue by introducing the Correlation Aware Pruner (CAP), a new unstructured pruning framework which significantly pushes the compressibility limits for state-of-the-art architectures.Our method is based on two technical advancements: a new theoretically-justified pruner, which can handle complex weight correlations accurately and efficiently during the pruning process itself, and an efficient finetuning procedure for post-compression recovery. We validate our approach via extensive experiments on several modern vision models such as Vision Transformers (ViT), modern CNNs, and ViT-CNN hybrids, showing for the first time that these can be pruned to high sparsity levels (e.g. $\geq 75$%) with low impact on accuracy ($\leq 1$% relative drop). Our approach is also compatible with structured pruning and quantization, and can lead to practical speedups of 1.5 to 2.4x without accuracy loss. To further showcase CAP's accuracy and scalability, we use it to show for the first time that extremely-accurate large vision models, trained via self-supervised techniques, can also be pruned to moderate sparsities, with negligible accuracy loss.
Video
Chat is not available.
Successful Page Load