Inner-Outer Aware Reconstruction Model for Monocular 3D Scene Reconstruction
{kind=link}
Abstract
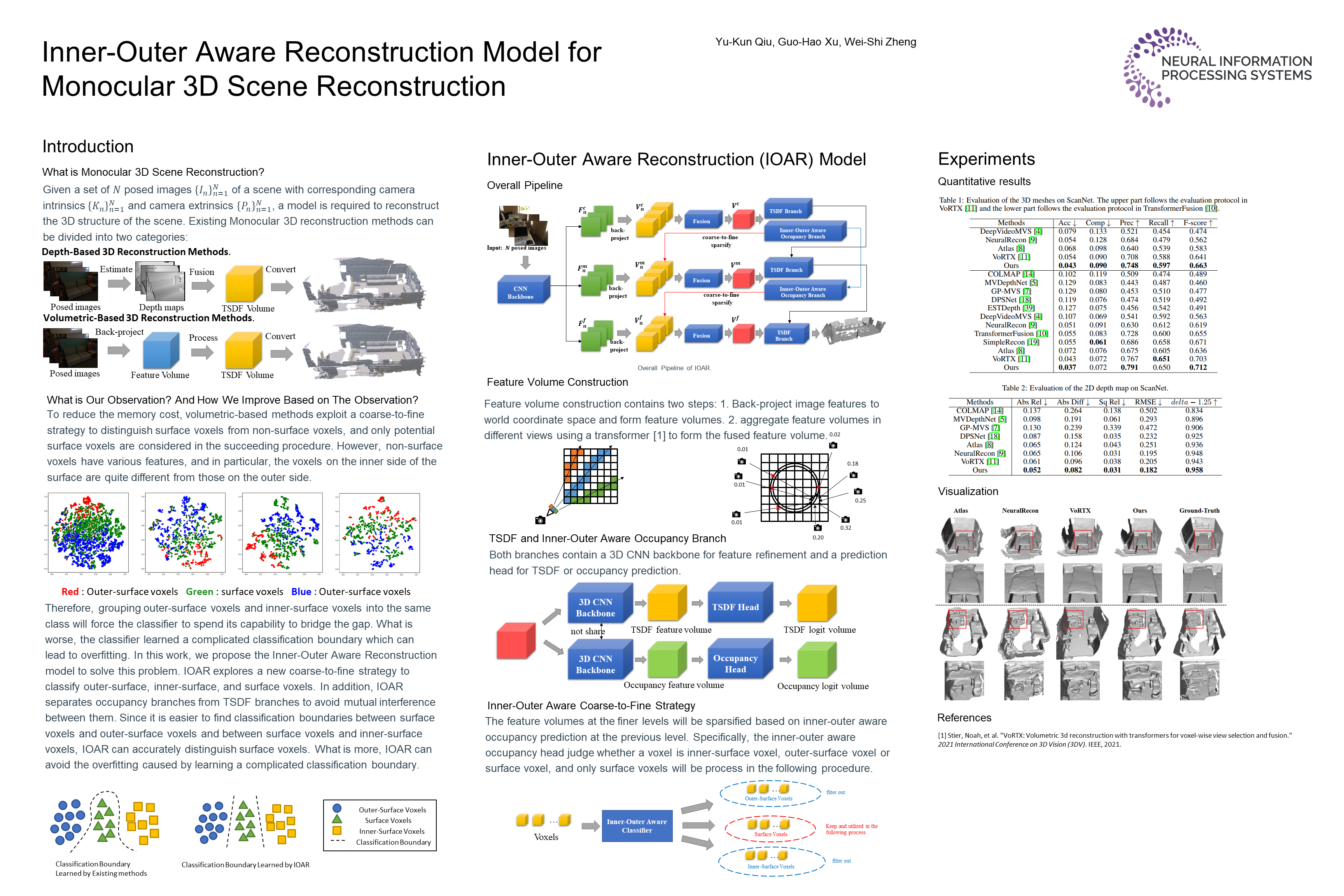
Monocular 3D scene reconstruction aims to reconstruct the 3D structure of scenes based on posed images. Recent volumetric-based methods directly predict the truncated signed distance function (TSDF) volume and have achieved promising results. The memory cost of volumetric-based methods will grow cubically as the volume size increases, so a coarse-to-fine strategy is necessary for saving memory. Specifically, the coarse-to-fine strategy distinguishes surface voxels from non-surface voxels, and only potential surface voxels are considered in the succeeding procedure. However, the non-surface voxels have various features, and in particular, the voxels on the inner side of the surface are quite different from those on the outer side since there exists an intrinsic gap between them. Therefore, grouping inner-surface and outer-surface voxels into the same class will force the classifier to spend its capacity to bridge the gap. By contrast, it is relatively easy for the classifier to distinguish inner-surface and outer-surface voxels due to the intrinsic gap. Inspired by this, we propose the inner-outer aware reconstruction (IOAR) model. IOAR explores a new coarse-to-fine strategy to classify outer-surface, inner-surface and surface voxels. In addition, IOAR separates occupancy branches from TSDF branches to avoid mutual interference between them. Since our model can better classify the surface, outer-surface and inner-surface voxels, it can predict more precise meshes than existing methods. Experiment results on ScanNet, ICL-NUIM and TUM-RGBD datasets demonstrate the effectiveness and generalization of our model. The code is available at https://github.com/YorkQiu/InnerOuterAwareReconstruction.