MIM4DD: Mutual Information Maximization for Dataset Distillation
{kind=link}
Abstract
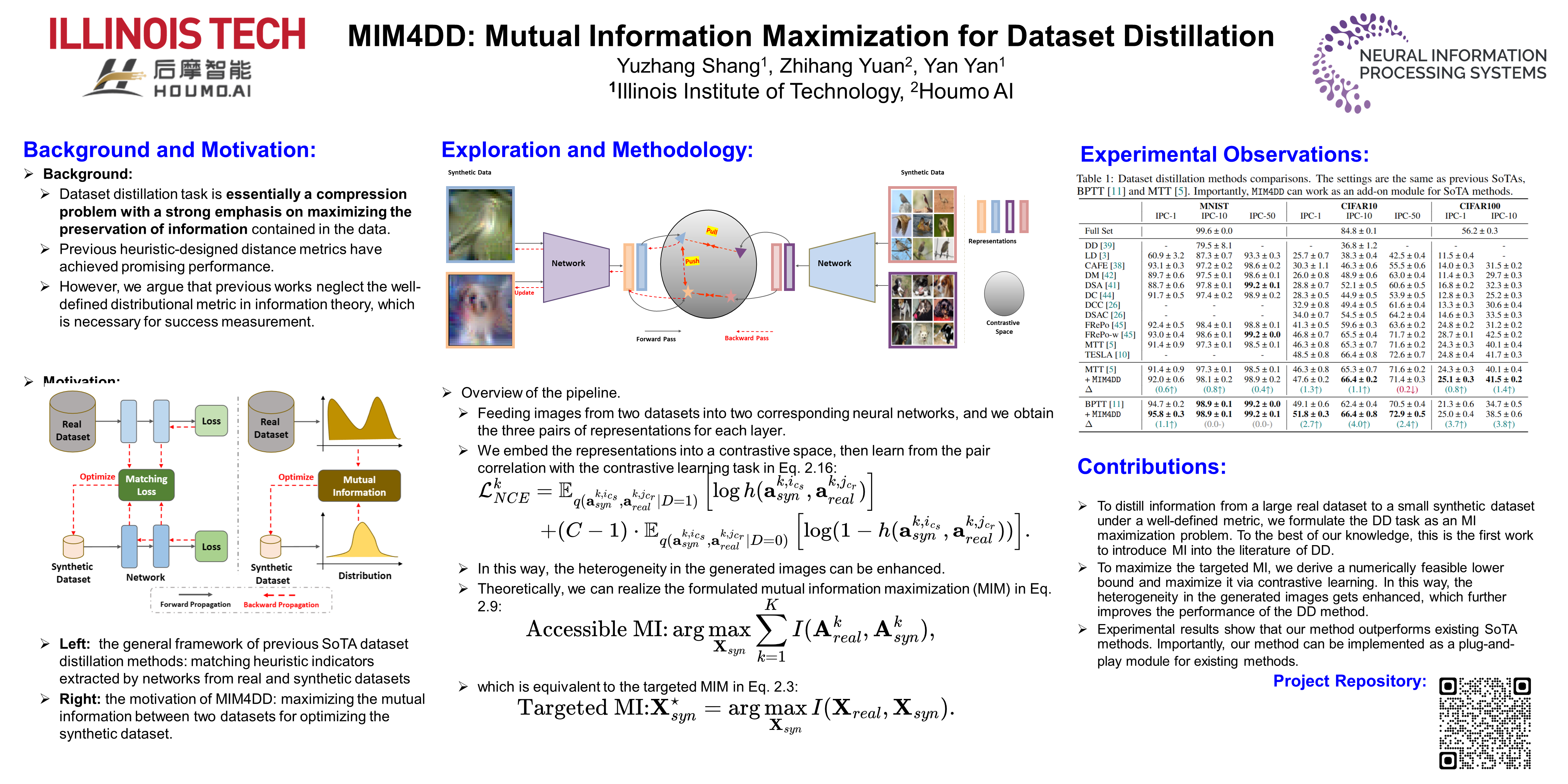
Dataset distillation (DD) aims to synthesize a small dataset whose test performance is comparable to a full dataset using the same model. State-of-the-art (SoTA) methods optimize synthetic datasets primarily by matching heuristic indicators extracted from two networks: one from real data and one from synthetic data (see Fig.1, Left), such as gradients and training trajectories. DD is essentially a compression problem that emphasizes on maximizing the preservation of information contained in the data. We argue that well-defined metrics which measure the amount of shared information between variables in information theory are necessary for success measurement, but are never considered by previous works. Thus, we introduce mutual information (MI) as the metric to quantify the shared information between the synthetic and the real datasets, and devise MIM4DD numerically maximizing the MI via a newly designed optimizable objective within a contrastive learning framework to update the synthetic dataset. Specifically, we designate the samples in different datasets who share the same labels as positive pairs, and vice versa negative pairs. Then we respectively pull and push those samples in positive and negative pairs into contrastive space via minimizing NCE loss. As a result, the targeted MI can be transformed into a lower bound represented by feature maps of samples, which is numerically feasible. Experiment results show that MIM4DD can be implemented as an add-on module to existing SoTA DD methods.