UNSSOR: Unsupervised Neural Speech Separation by Leveraging Over-determined Training Mixtures
Zhong-Qiu Wang ⋅ Shinji Watanabe
2023 Poster
{kind=link}
Abstract
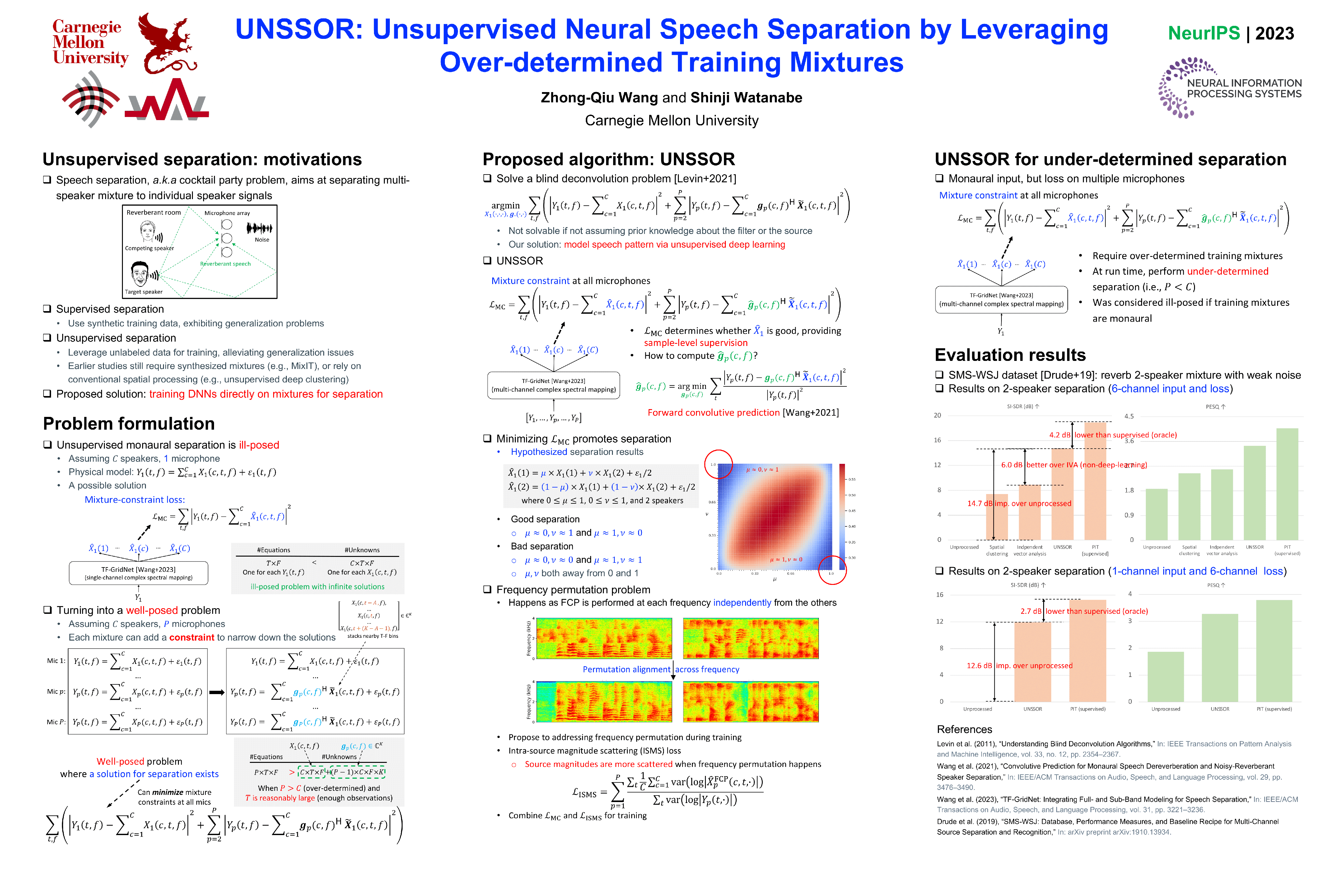
In reverberant conditions with multiple concurrent speakers, each microphone acquires a mixture signal of multiple speakers at a different location. In over-determined conditions where the microphones out-number speakers, we can narrow down the solutions to speaker images and realize unsupervised speech separation by leveraging each mixture signal as a constraint (i.e., the estimated speaker images at a microphone should add up to the mixture). Equipped with this insight, we propose UNSSOR, an algorithm for $\underline{u}$nsupervised $\underline{n}$eural $\underline{s}$peech $\underline{s}$eparation by leveraging $\underline{o}$ver-determined training mixtu$\underline{r}$es. At each training step, we feed an input mixture to a deep neural network (DNN) to produce an intermediate estimate for each speaker, linearly filter the estimates, and optimize a loss so that, at each microphone, the filtered estimates of all the speakers can add up to the mixture to satisfy the above constraint. We show that this loss can promote unsupervised separation of speakers. The linear filters are computed in each sub-band based on the mixture and DNN estimates through the forward convolutive prediction (FCP) algorithm. To address the frequency permutation problem incurred by using sub-band FCP, a loss term based on minimizing intra-source magnitude scattering is proposed. Although UNSSOR requires over-determined training mixtures, we can train DNNs to achieve under-determined separation (e.g., unsupervised monaural speech separation). Evaluation results on two-speaker separation in reverberant conditions show the effectiveness and potential of UNSSOR.
Video
Chat is not available.
Successful Page Load