MomentDiff: Generative Video Moment Retrieval from Random to Real
{kind=link}
Abstract
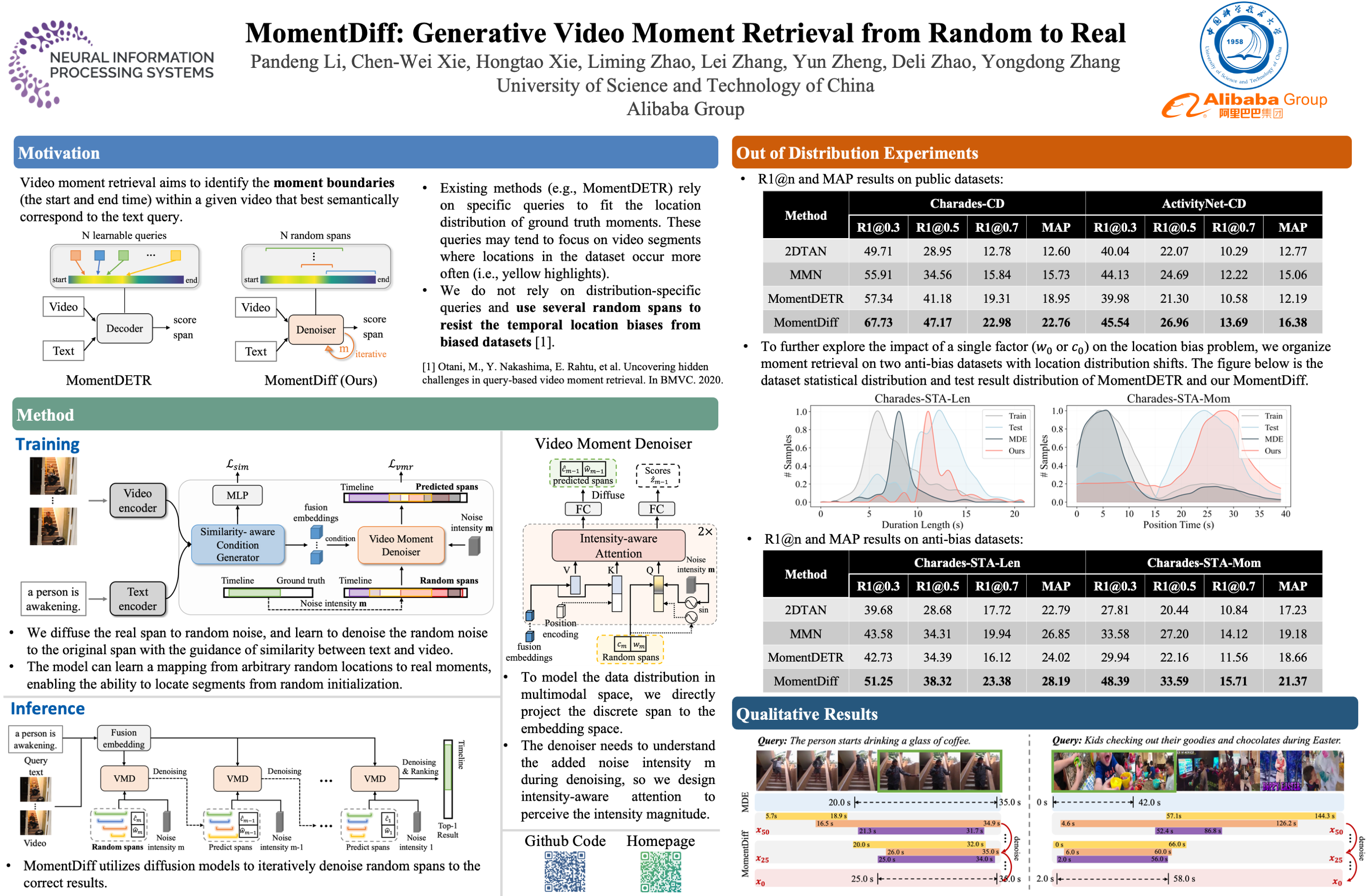
Video moment retrieval pursues an efficient and generalized solution to identify the specific temporal segments within an untrimmed video that correspond to a given language description.To achieve this goal, we provide a generative diffusion-based framework called MomentDiff, which simulates a typical human retrieval process from random browsing to gradual localization.Specifically, we first diffuse the real span to random noise, and learn to denoise the random noise to the original span with the guidance of similarity between text and video.This allows the model to learn a mapping from arbitrary random locations to real moments, enabling the ability to locate segments from random initialization.Once trained, MomentDiff could sample random temporal segments as initial guesses and iteratively refine them to generate an accurate temporal boundary.Different from discriminative works (e.g., based on learnable proposals or queries), MomentDiff with random initialized spans could resist the temporal location biases from datasets.To evaluate the influence of the temporal location biases, we propose two ``anti-bias'' datasets with location distribution shifts, named Charades-STA-Len and Charades-STA-Mom.The experimental results demonstrate that our efficient framework consistently outperforms state-of-the-art methods on three public benchmarks, and exhibits better generalization and robustness on the proposed anti-bias datasets. The code, model, and anti-bias evaluation datasets will be released publicly.