Cluster-aware Semi-supervised Learning: Relational Knowledge Distillation Provably Learns Clustering
{kind=link}
Abstract
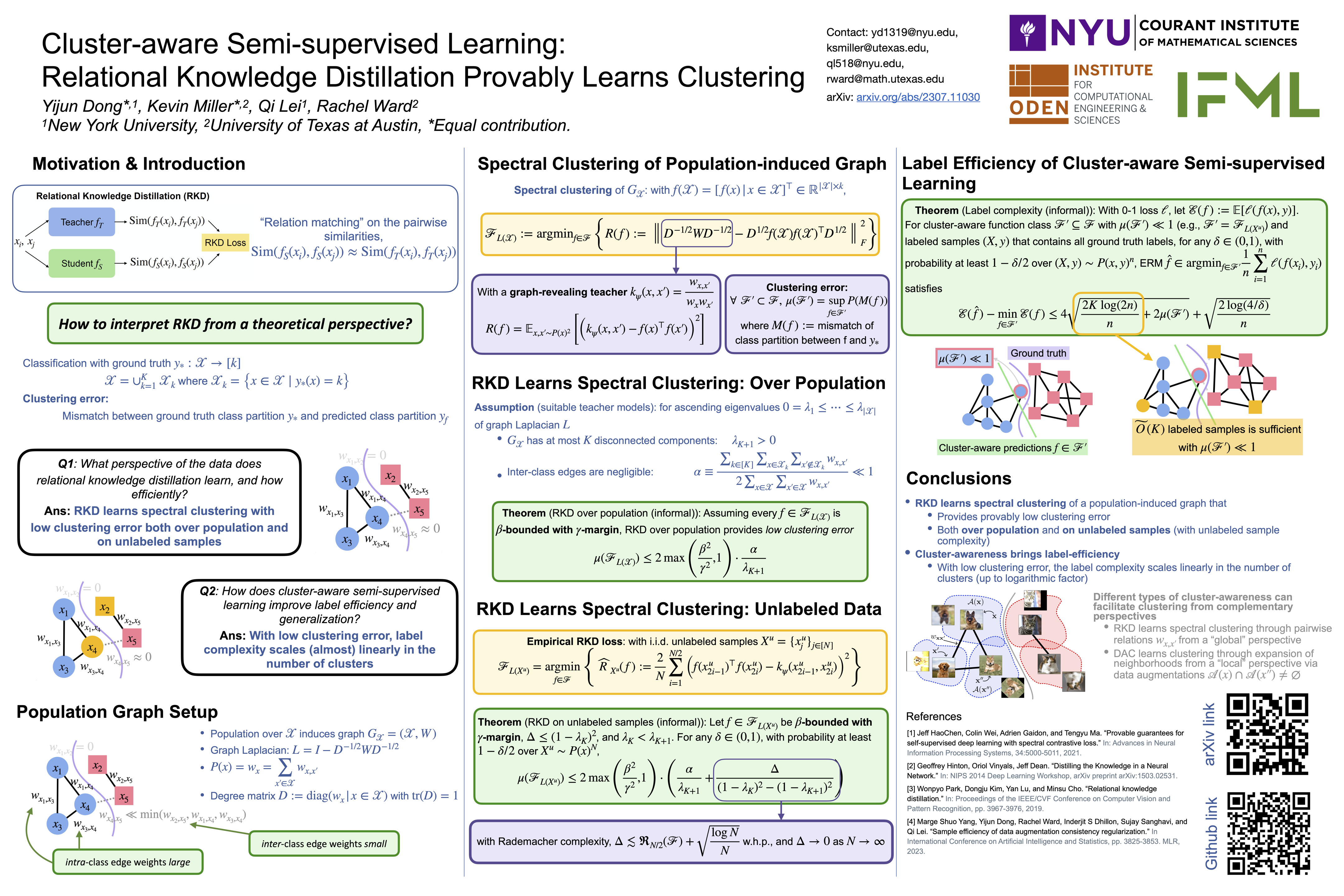
Despite the empirical success and practical significance of (relational) knowledge distillation that matches (the relations of) features between teacher and student models, the corresponding theoretical interpretations remain limited for various knowledge distillation paradigms. In this work, we take an initial step toward a theoretical understanding of relational knowledge distillation (RKD), with a focus on semi-supervised classification problems. We start by casting RKD as spectral clustering on a population-induced graph unveiled by a teacher model. Via a notion of clustering error that quantifies the discrepancy between the predicted and ground truth clusterings, we illustrate that RKD over the population provably leads to low clustering error. Moreover, we provide a sample complexity bound for RKD with limited unlabeled samples. For semi-supervised learning, we further demonstrate the label efficiency of RKD through a general framework of cluster-aware semi-supervised learning that assumes low clustering errors. Finally, by unifying data augmentation consistency regularization into this cluster-aware framework, we show that despite the common effect of learning accurate clusterings, RKD facilitates a "global" perspective through spectral clustering, whereas consistency regularization focuses on a "local" perspective via expansion.