Reverse Engineering Self-Supervised Learning
{kind=link}
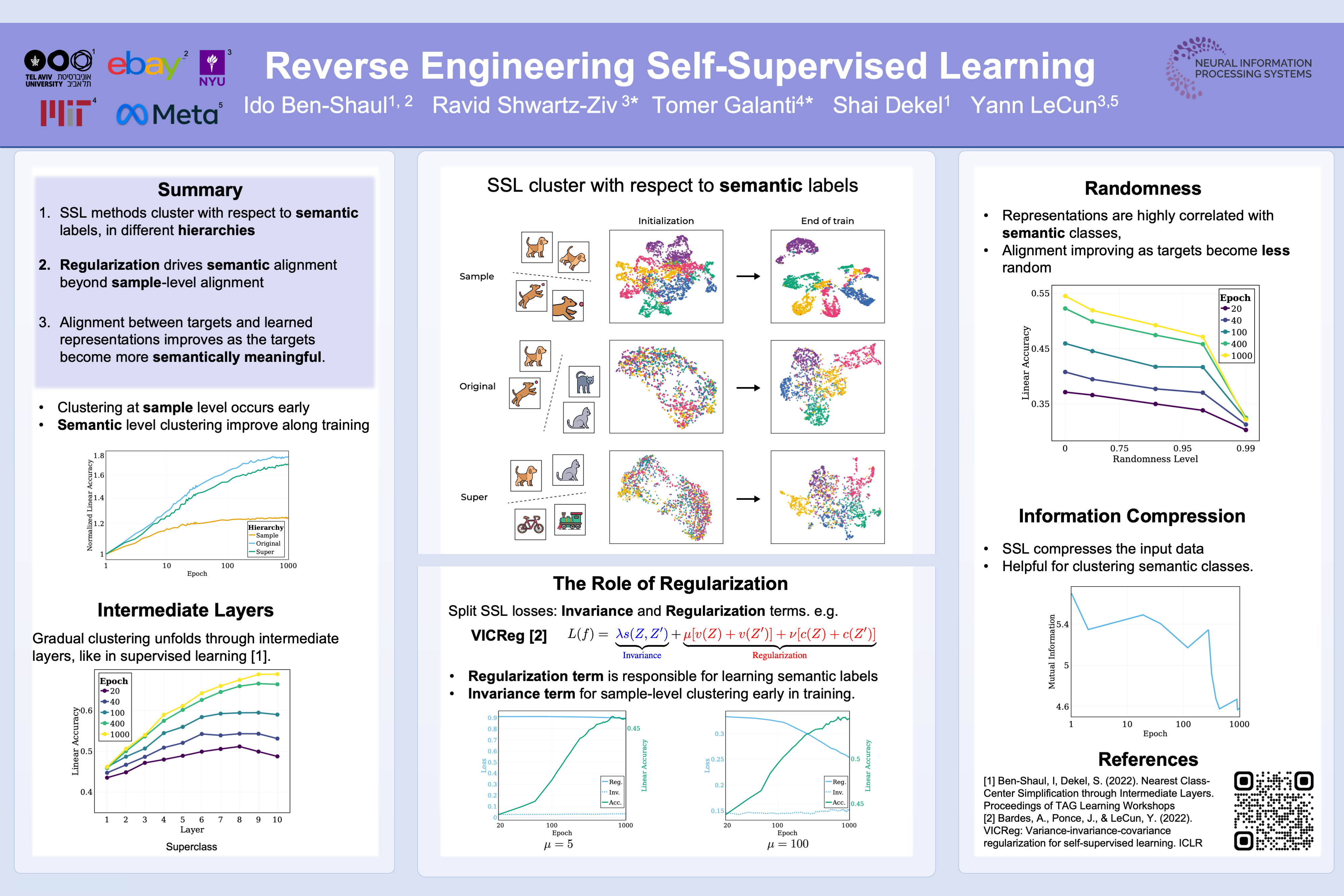
Abstract
Understanding the learned representation and underlying mechanisms of Self-Supervised Learning (SSL) often poses a challenge. In this paper, we ‘reverse engineer’ SSL, conducting an in-depth empirical analysis of its learned internal representations, encompassing diverse models, architectures, and hyperparameters. Our study reveals an intriguing process within the SSL training: an inherent facilitation of semantic label-based clustering, which is surprisingly driven by the regularization component of the SSL objective. This clustering not only enhances downstream classification, but also compresses the information. We further illustrate that the alignment of the SSL-trained representation is more pronounced with semantic classes rather than random functions. Remarkably, the learned representations align with semantic classes across various hierarchical levels, with this alignment intensifying when going deeper into the network. This ‘reverse engineering’ approach provides valuable insights into the inner mechanism of SSL and their influences on the performance across different class sets.