Restless Bandits with Average Reward: Breaking the Uniform Global Attractor Assumption
Yige Hong ⋅ Qiaomin Xie ⋅ Yudong Chen ⋅ Weina Wang
2023 Spotlight Poster
{kind=link}
Abstract
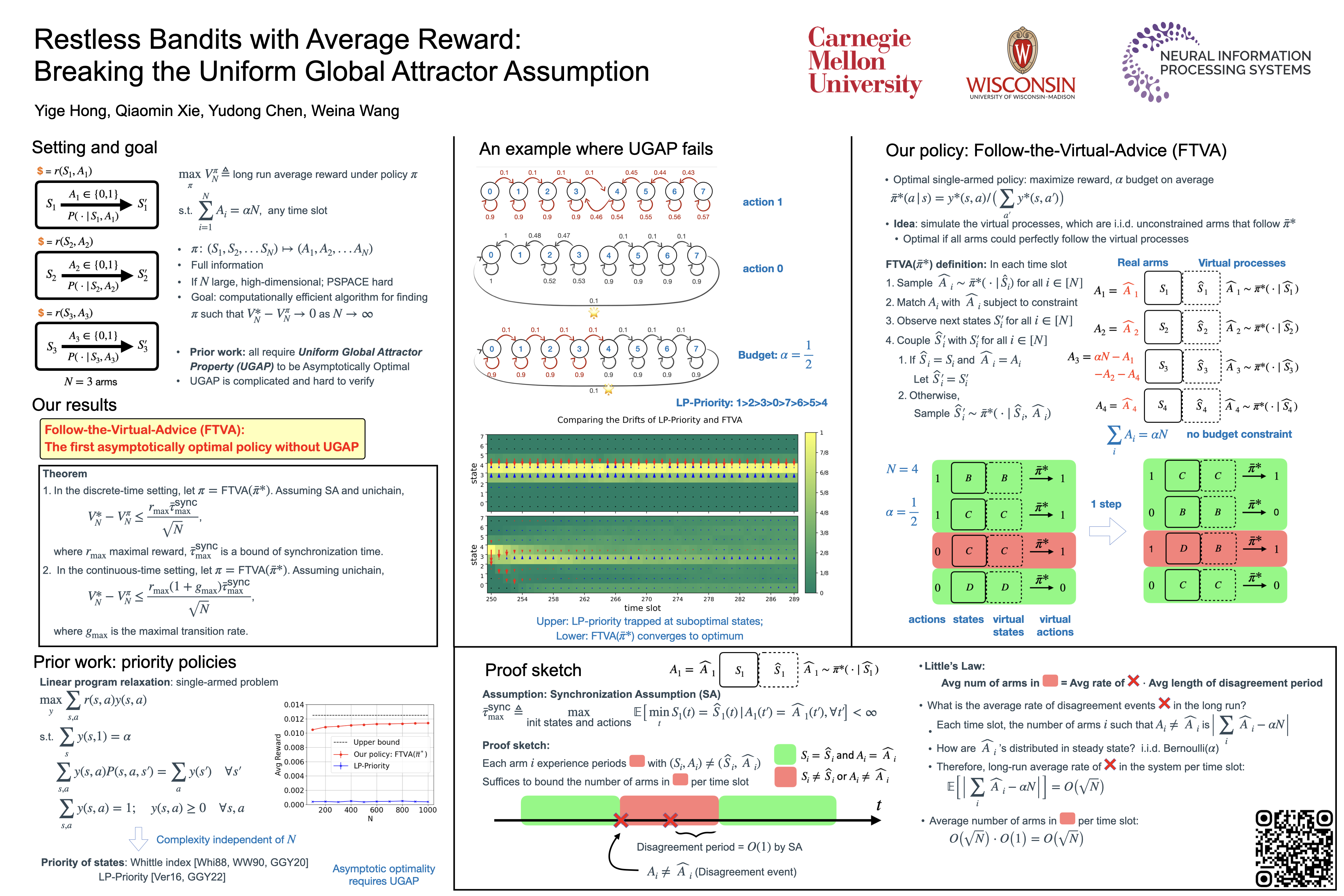
We study the infinite-horizon restless bandit problem with the average reward criterion, in both discrete-time and continuous-time settings.A fundamental goal is to efficiently compute policies that achieve a diminishing optimality gap as the number of arms, $N$, grows large. Existing results on asymptotic optimality all rely on the uniform global attractor property (UGAP), a complex and challenging-to-verify assumption. In this paper, we propose a general, simulation-based framework, Follow-the-Virtual-Advice, that converts any single-armed policy into a policy for the original $N$-armed problem. This is done by simulating the single-armed policy on each arm and carefully steering the real state towards the simulated state. Our framework can be instantiated to produce a policy with an $O(1/\sqrt{N})$ optimality gap. In the discrete-time setting, our result holds under a simpler synchronization assumption, which covers some problem instances that violate UGAP. More notably, in the continuous-time setting, we do not require \emph{any} additional assumptions beyond the standard unichain condition. In both settings, our work is the first asymptotic optimality result that does not require UGAP.
Video
Chat is not available.
Successful Page Load