Bridging the Domain Gap: Self-Supervised 3D Scene Understanding with Foundation Models
{kind=link}
Abstract
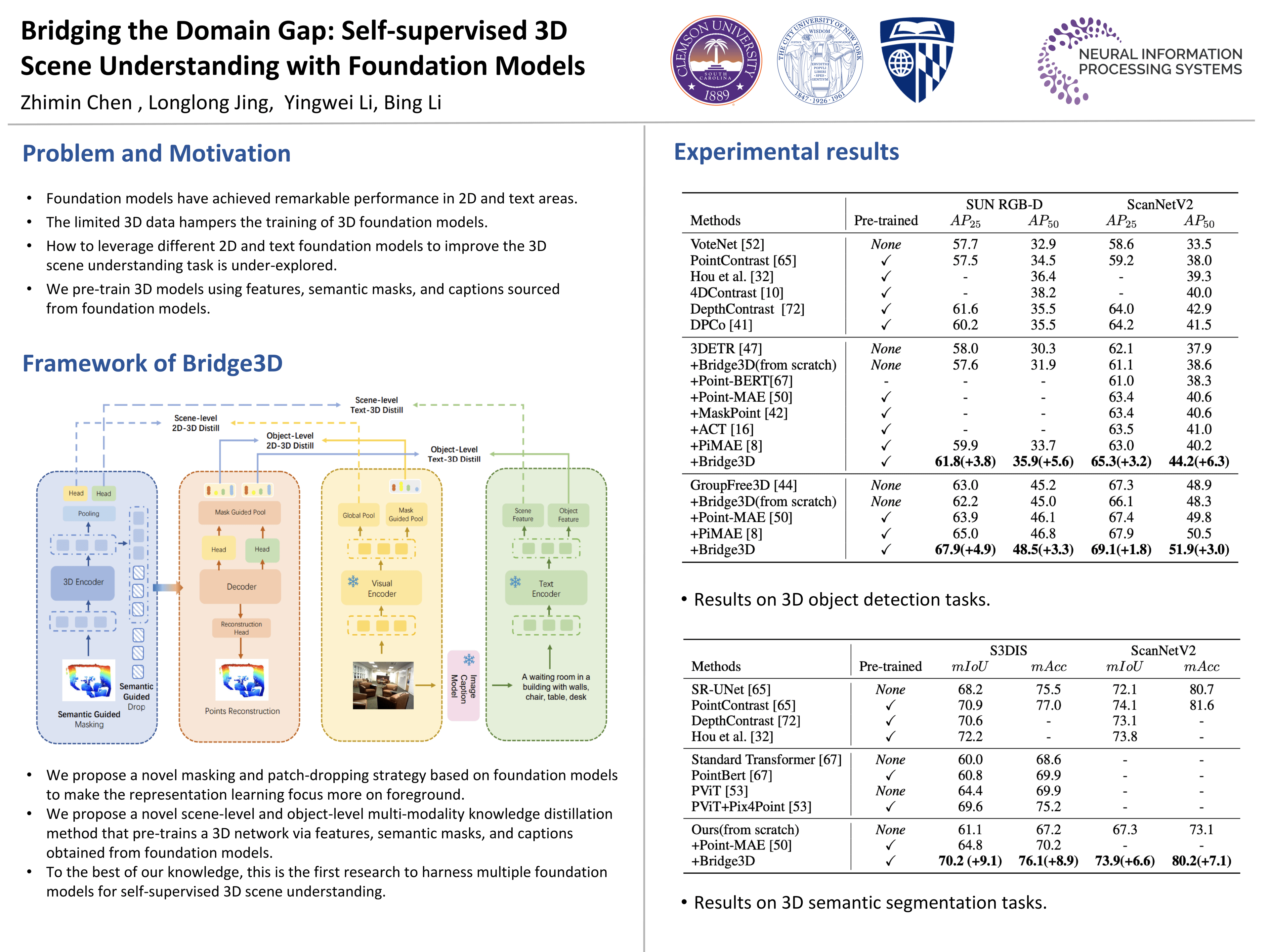
Foundation models have achieved remarkable results in 2D and language tasks like image segmentation, object detection, and visual-language understanding. However, their potential to enrich 3D scene representation learning is largely untapped due to the existence of the domain gap. In this work, we propose an innovative methodology called Bridge3D to address this gap by pre-training 3D models using features, semantic masks, and captions sourced from foundation models. Specifically, our method employs semantic masks from foundation models to guide the masking and reconstruction process for the masked autoencoder, enabling more focused attention on foreground representations. Moreover, we bridge the 3D-text gap at the scene level using image captioning foundation models, thereby facilitating scene-level knowledge distillation. We further extend this bridging effort by introducing an innovative object-level knowledge distillation method that harnesses highly accurate object-level masks and semantic text data from foundation models. Our methodology significantly surpasses the performance of existing state-of-the-art methods in 3D object detection and semantic segmentation tasks. For instance, on the ScanNet dataset, Bridge3D improves the baseline by a notable margin of 6.3%. Code will be available at: https://github.com/Zhimin-C/Bridge3D