Learning Visual Prior via Generative Pre-Training
{kind=link}
Abstract
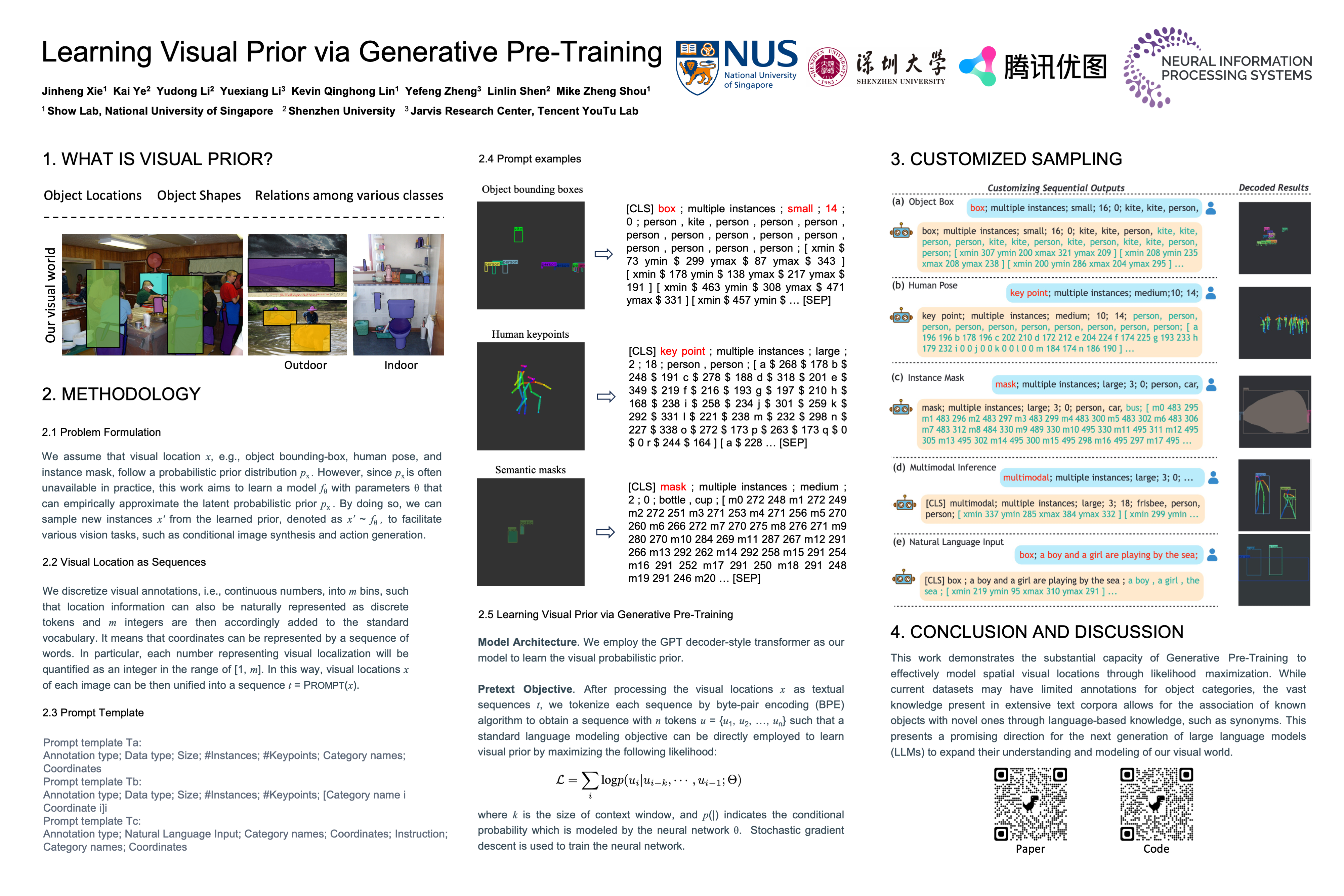
Various stuff and things in visual data possess specific traits, which can be learned by deep neural networks and are implicitly represented as the visual prior, e.g., object location and shape, in the model. Such prior potentially impacts many vision tasks. For example, in conditional image synthesis, spatial conditions failing to adhere to the prior can result in visually inaccurate synthetic results. This work aims to explicitly learn the visual prior and enable the customization of sampling. Inspired by advances in language modeling, we propose to learn Visual prior via Generative Pre-Training, dubbed VisorGPT. By discretizing visual locations, e.g., bounding boxes, human pose, and instance masks, into sequences, VisorGPT can model visual prior through likelihood maximization. Besides, prompt engineering is investigated to unify various visual locations and enable customized sampling of sequential outputs from the learned prior. Experimental results demonstrate the effectiveness of VisorGPT in modeling visual prior and extrapolating to novel scenes, potentially motivating that discrete visual locations can be integrated into the learning paradigm of current language models to further perceive visual world. Code is available at https://sierkinhane.github.io/visor-gpt.