Glance and Focus: Memory Prompting for Multi-Event Video Question Answering
{kind=link}
Abstract
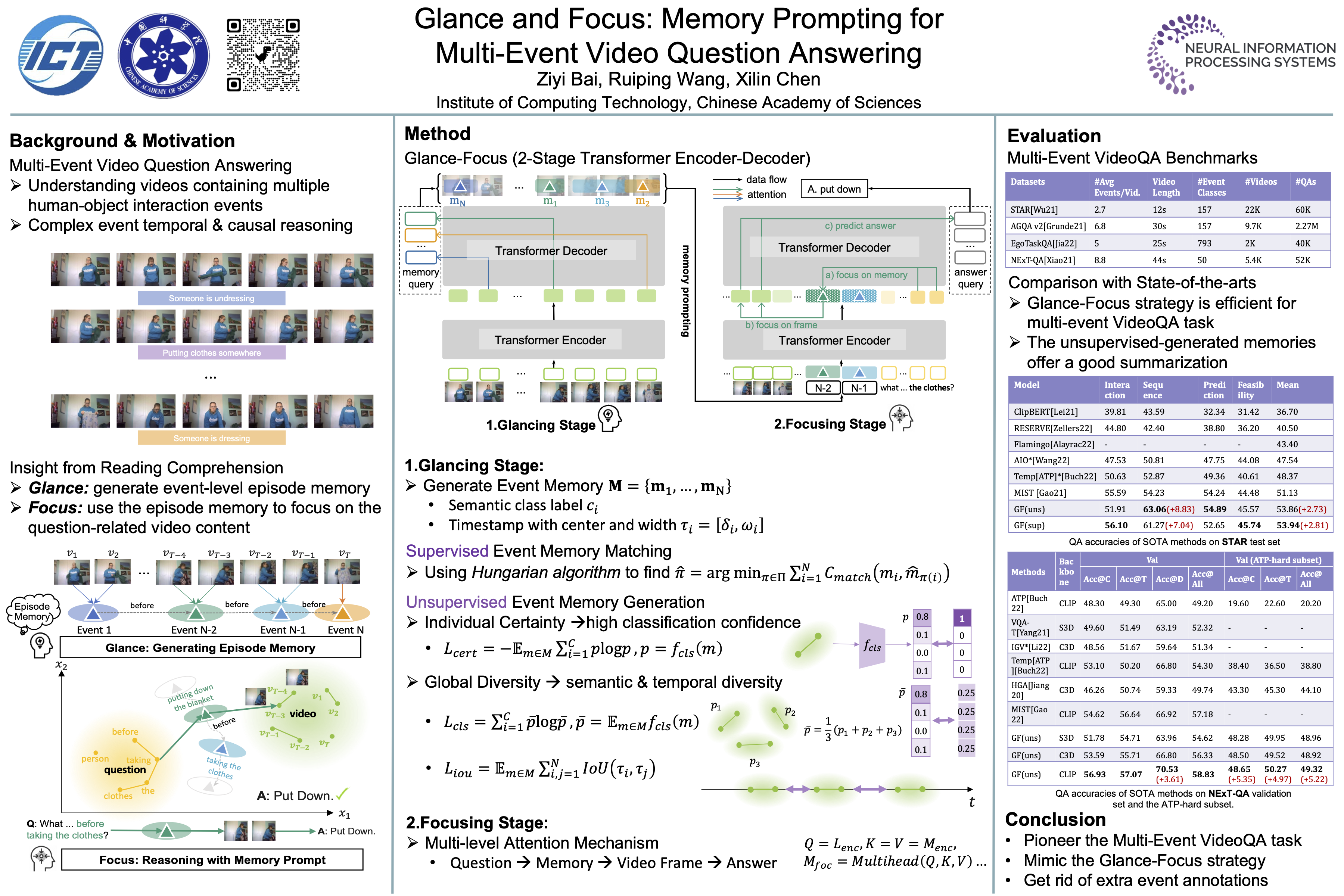
Video Question Answering (VideoQA) has emerged as a vital tool to evaluate agents’ ability to understand human daily behaviors. Despite the recent success of large vision language models in many multi-modal tasks, complex situation reasoning over videos involving multiple human-object interaction events still remains challenging. In contrast, humans can easily tackle it by using a series of episode memories as anchors to quickly locate question-related key moments for reasoning. To mimic this effective reasoning strategy, we propose the Glance- Focus model. One simple way is to apply an action detection model to predict a set of actions as key memories. However, these actions within a closed set vocabulary are hard to generalize to various video domains. Instead of that, we train an Encoder-Decoder to generate a set of dynamic event memories at the glancing stage. Apart from using supervised bipartite matching to obtain the event memories, we further design an unsupervised memory generation method to get rid of dependence on event annotations. Next, at the focusing stage, these event memories act as a bridge to establish the correlation between the questions with high-level event concepts and low-level lengthy video content. Given the question, the model first focuses on the generated key event memory, then focuses on the most relevant moment for reasoning through our designed multi-level cross- attention mechanism. We conduct extensive experiments on four Multi-Event VideoQA benchmarks including STAR, EgoTaskQA, AGQA, and NExT-QA. Our proposed model achieves state-of-the-art results, surpassing current large models in various challenging reasoning tasks. The code and models are available at https://github.com/ByZ0e/Glance-Focus.