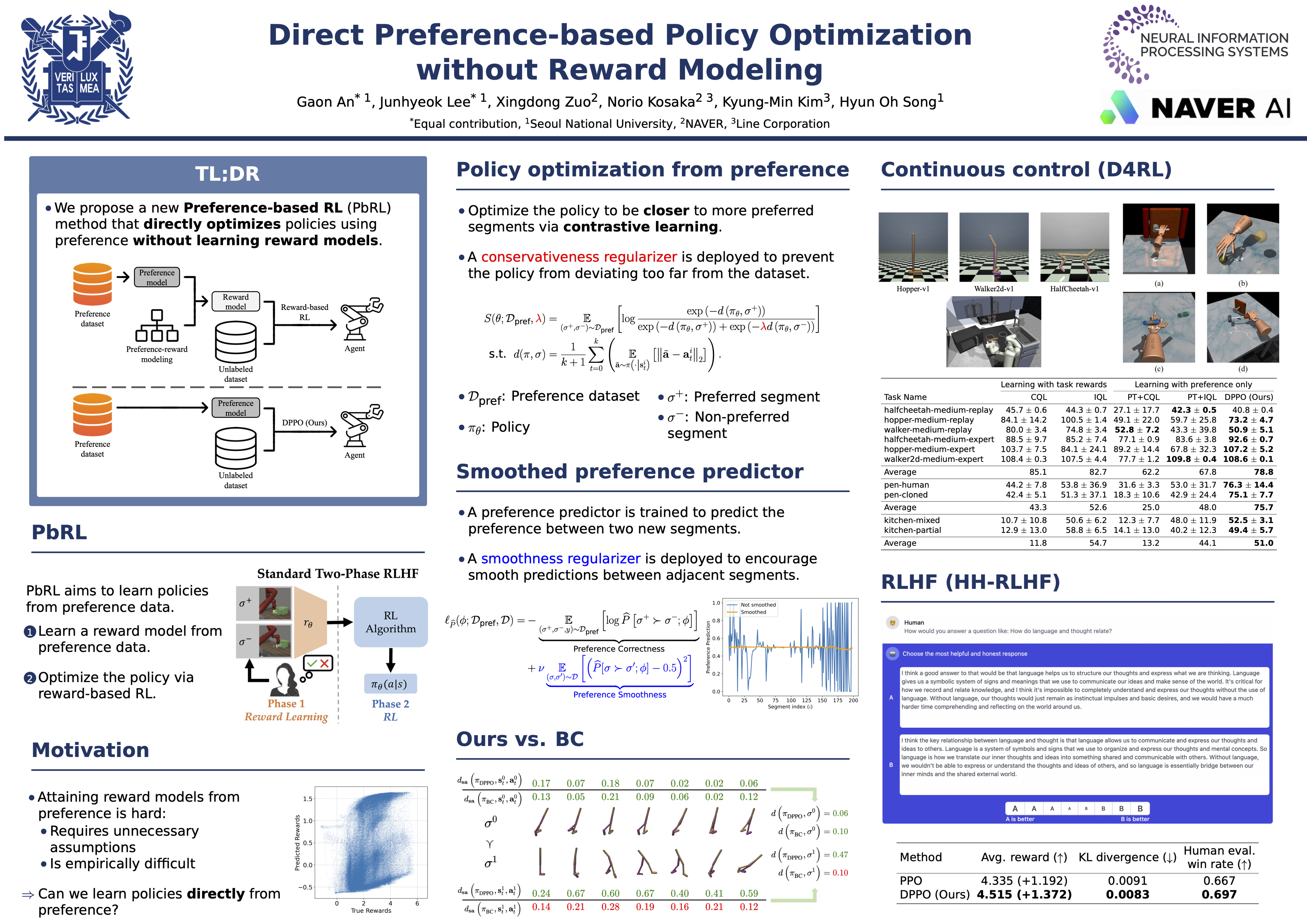
Direct Preference-based Policy Optimization without Reward Modeling
{kind=link}
Abstract
Preference-based reinforcement learning (PbRL) is an approach that enables RL agents to learn from preference, which is particularly useful when formulating a reward function is challenging. Existing PbRL methods generally involve a two-step procedure: they first learn a reward model based on given preference data and then employ off-the-shelf reinforcement learning algorithms using the learned reward model. However, obtaining an accurate reward model solely from preference information, especially when the preference is from human teachers, can be difficult. Instead, we propose a PbRL algorithm that directly learns from preference without requiring any reward modeling. To achieve this, we adopt a contrastive learning framework to design a novel policy scoring metric that assigns a high score to policies that align with the given preferences. We apply our algorithm to offline RL tasks with actual human preference labels and show that our algorithm outperforms or is on par with the existing PbRL methods. Notably, on high-dimensional control tasks, our algorithm surpasses offline RL methods that learn with ground-truth reward information. Finally, we show that our algorithm can be successfully applied to fine-tune large language models.