Mnemosyne: Learning to Train Transformers with Transformers
{kind=link}
Abstract
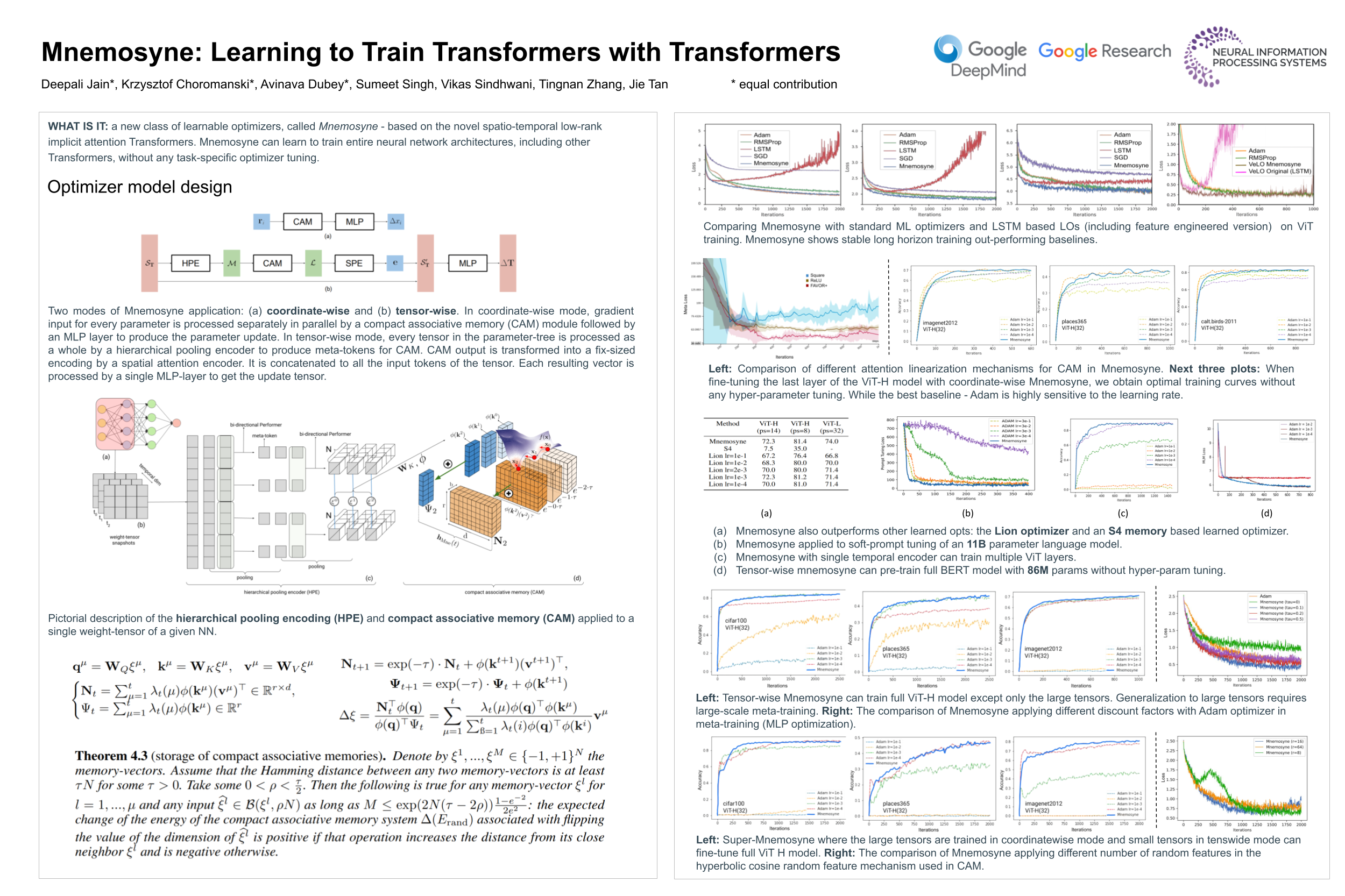
In this work, we propose a new class of learnable optimizers, called Mnemosyne. It is based on the novel spatio-temporal low-rank implicit attention Transformers that can learn to train entire neural network architectures, including other Transformers, without any task-specific optimizer tuning. We show that Mnemosyne: (a) outperforms popular LSTM optimizers (also with new feature engineering to mitigate catastrophic forgetting of LSTMs), (b) can successfully train Transformers while using simple meta-training strategies that require minimal computational resources, (c) matches accuracy-wise SOTA hand-designed optimizers with carefully tuned hyper-parameters (often producing top performing models). Furthermore, Mnemosyne provides space complexity comparable to that of its hand-designed first-order counterparts, which allows it to scale to training larger sets of parameters. We conduct an extensive empirical evaluation of Mnemosyne on: (a) fine-tuning a wide range of Vision Transformers (ViTs) from medium-size architectures to massive ViT-Hs (36 layers, 16 heads), (b) pre-training BERT models and (c) soft prompt-tuning large 11B+ T5XXL models. We complement our results with a comprehensive theoretical analysis of the compact associative memory used by Mnemosyne which we believe was never done before.