Sample Complexity of Goal-Conditioned Hierarchical Reinforcement Learning
Arnaud Robert ⋅ Ciara Pike-Burke ⋅ Aldo Faisal
2023 Poster
{kind=link}
Abstract
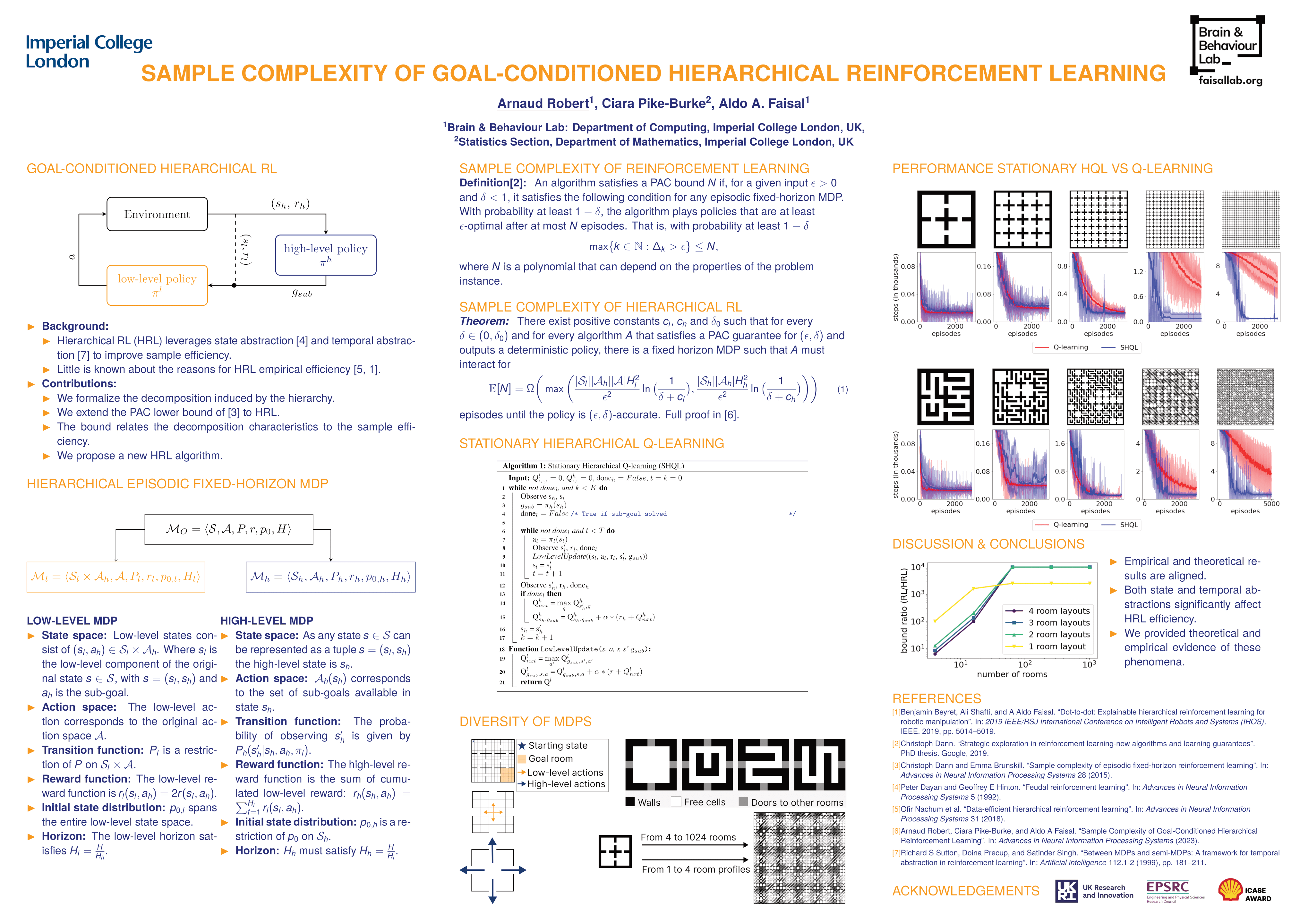
Hierarchical Reinforcement Learning (HRL) algorithms can perform planning at multiple levels of abstraction. Empirical results have shown that state or temporal abstractions might significantly improve the sample efficiency of algorithms. Yet, we still do not have a complete understanding of the basis of those efficiency gains nor any theoretically grounded design rules. In this paper, we derive a lower bound on the sample complexity for the considered class of goal-conditioned HRL algorithms. The proposed lower bound empowers us to quantify the benefits of hierarchical decomposition and leads to the design of a simple Q-learning-type algorithm that leverages hierarchical decompositions. We empirically validate our theoretical findings by investigating the sample complexity of the proposed hierarchical algorithm on a spectrum of tasks (hierarchical $n$-rooms, Gymnasium's Taxi). The hierarchical $n$-rooms tasks were designed to allow us to dial their complexity over multiple orders of magnitude. Our theory and algorithmic findings provide a step towards answering the foundational question of quantifying the improvement hierarchical decomposition offers over monolithic solutions in reinforcement learning.
Video
Chat is not available.
Successful Page Load