Systematic Visual Reasoning through Object-Centric Relational Abstraction
{kind=link}
Abstract
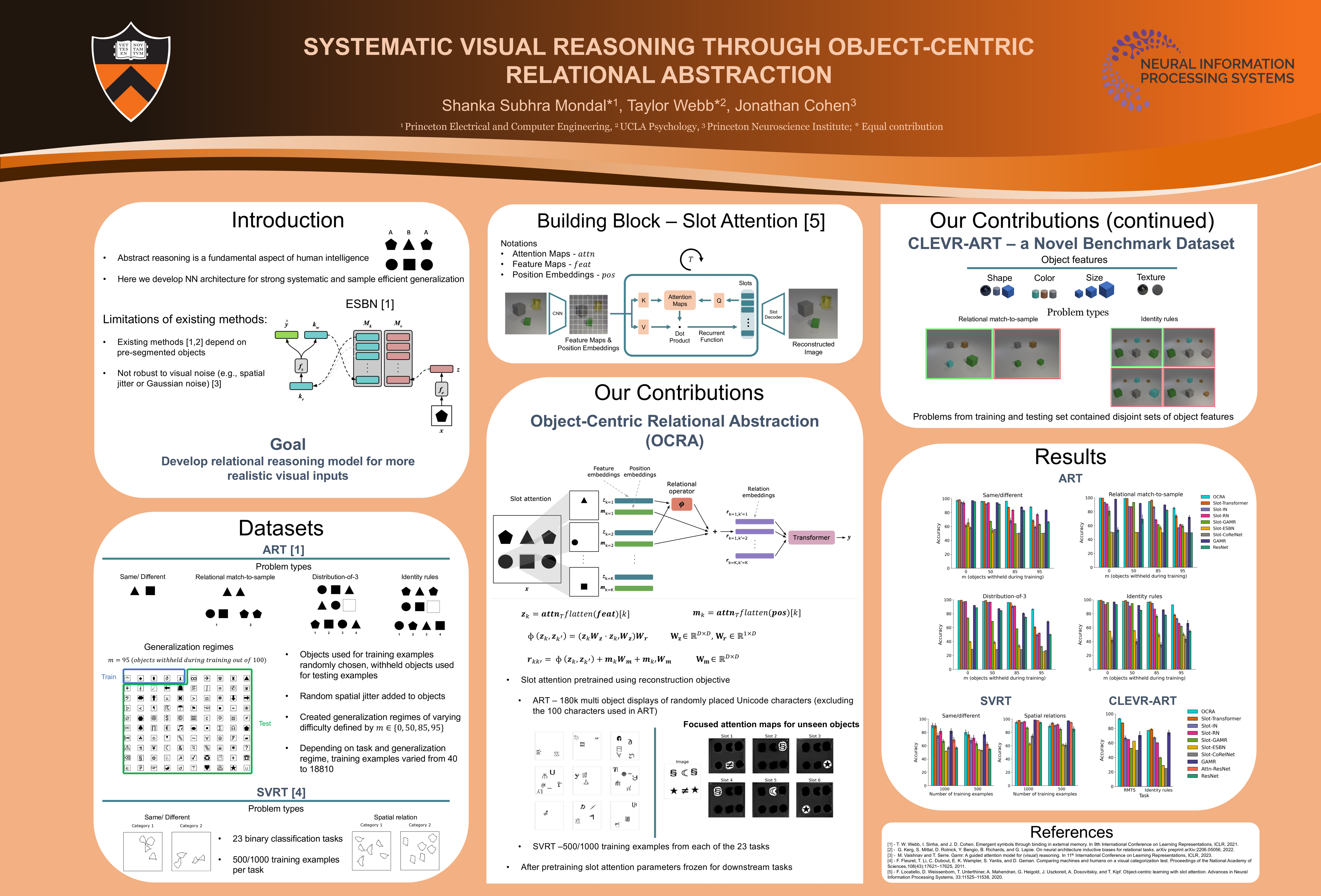
Human visual reasoning is characterized by an ability to identify abstract patterns from only a small number of examples, and to systematically generalize those patterns to novel inputs. This capacity depends in large part on our ability to represent complex visual inputs in terms of both objects and relations. Recent work in computer vision has introduced models with the capacity to extract object-centric representations, leading to the ability to process multi-object visual inputs, but falling short of the systematic generalization displayed by human reasoning. Other recent models have employed inductive biases for relational abstraction to achieve systematic generalization of learned abstract rules, but have generally assumed the presence of object-focused inputs. Here, we combine these two approaches, introducing Object-Centric Relational Abstraction (OCRA), a model that extracts explicit representations of both objects and abstract relations, and achieves strong systematic generalization in tasks (including a novel dataset, CLEVR-ART, with greater visual complexity) involving complex visual displays.