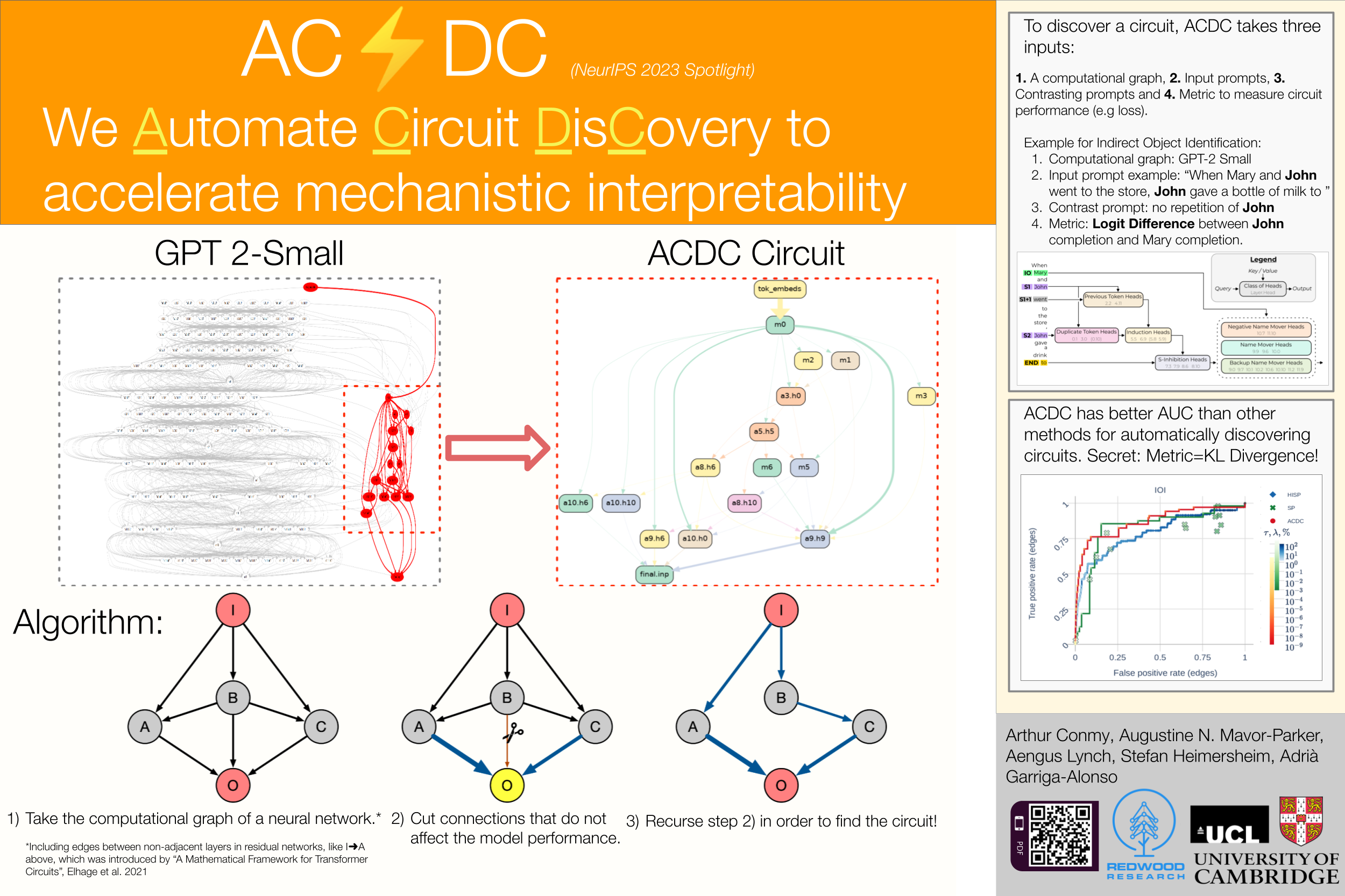
Towards Automated Circuit Discovery for Mechanistic Interpretability
{kind=link}
Abstract
Through considerable effort and intuition, several recent works have reverse-engineered nontrivial behaviors oftransformer models. This paper systematizes the mechanistic interpretability process they followed. First, researcherschoose a metric and dataset that elicit the desired model behavior. Then, they apply activation patching to find whichabstract neural network units are involved in the behavior. By varying the dataset, metric, and units underinvestigation, researchers can understand the functionality of each component.We automate one of the process' steps: finding the connections between the abstract neural network units that form a circuit. We propose several algorithms and reproduce previous interpretability results to validate them. Forexample, the ACDC algorithm rediscovered 5/5 of the component types in a circuit in GPT-2 Small that computes theGreater-Than operation. ACDC selected 68 of the 32,000 edges in GPT-2 Small, all of which were manually found byprevious work. Our code is available at https://github.com/ArthurConmy/Automatic-Circuit-Discovery