Importance Weighted Actor-Critic for Optimal Conservative Offline Reinforcement Learning
Hanlin Zhu ⋅ Paria Rashidinejad ⋅ Jiantao Jiao
2023 Poster
{kind=link}
Abstract
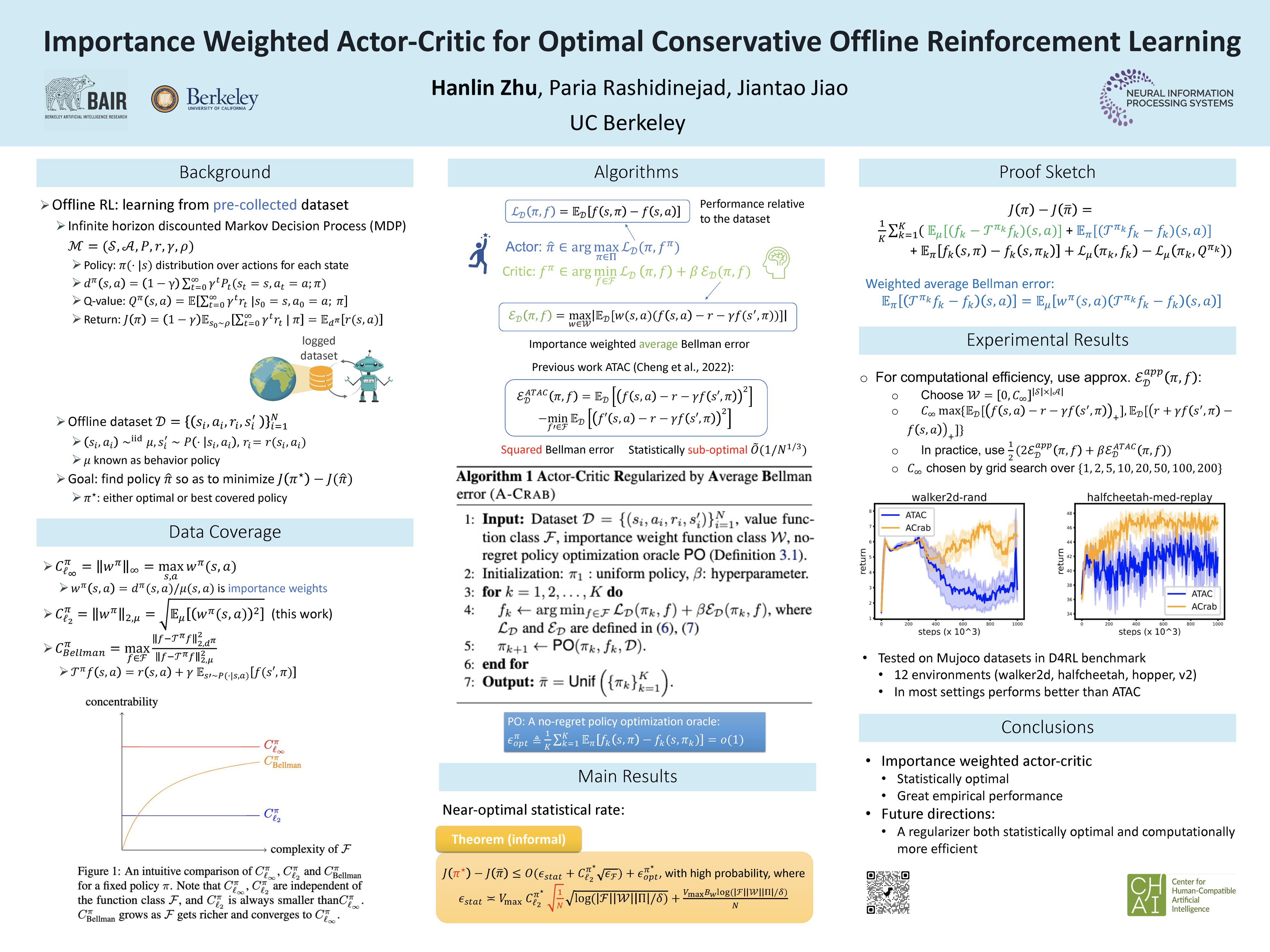
We propose A-Crab (Actor-Critic Regularized by Average Bellman error), a new practical algorithm for offline reinforcement learning (RL) in complex environments with insufficient data coverage. Our algorithm combines the marginalized importance sampling framework with the actor-critic paradigm, where the critic returns evaluations of the actor (policy) that are pessimistic relative to the offline data and have a small average (importance-weighted) Bellman error. Compared to existing methods, our algorithm simultaneously offers a number of advantages:(1) It achieves the optimal statistical rate of $1/\sqrt{N}$---where $N$ is the size of offline dataset---in converging to the best policy covered in the offline dataset, even when combined with general function approximators.(2) It relies on a weaker \textit{average} notion of policy coverage (compared to the $\ell_\infty$ single-policy concentrability) that exploits the structure of policy visitations.(3) It outperforms the data-collection behavior policy over a wide range of specific hyperparameters. We provide both theoretical analysis and experimental results to validate the effectiveness of our proposed algorithm. The code is available at https://github.com/zhuhl98/ACrab.
Video
Chat is not available.
Successful Page Load