Segment Anything in 3D with NeRFs
{kind=link}
Abstract
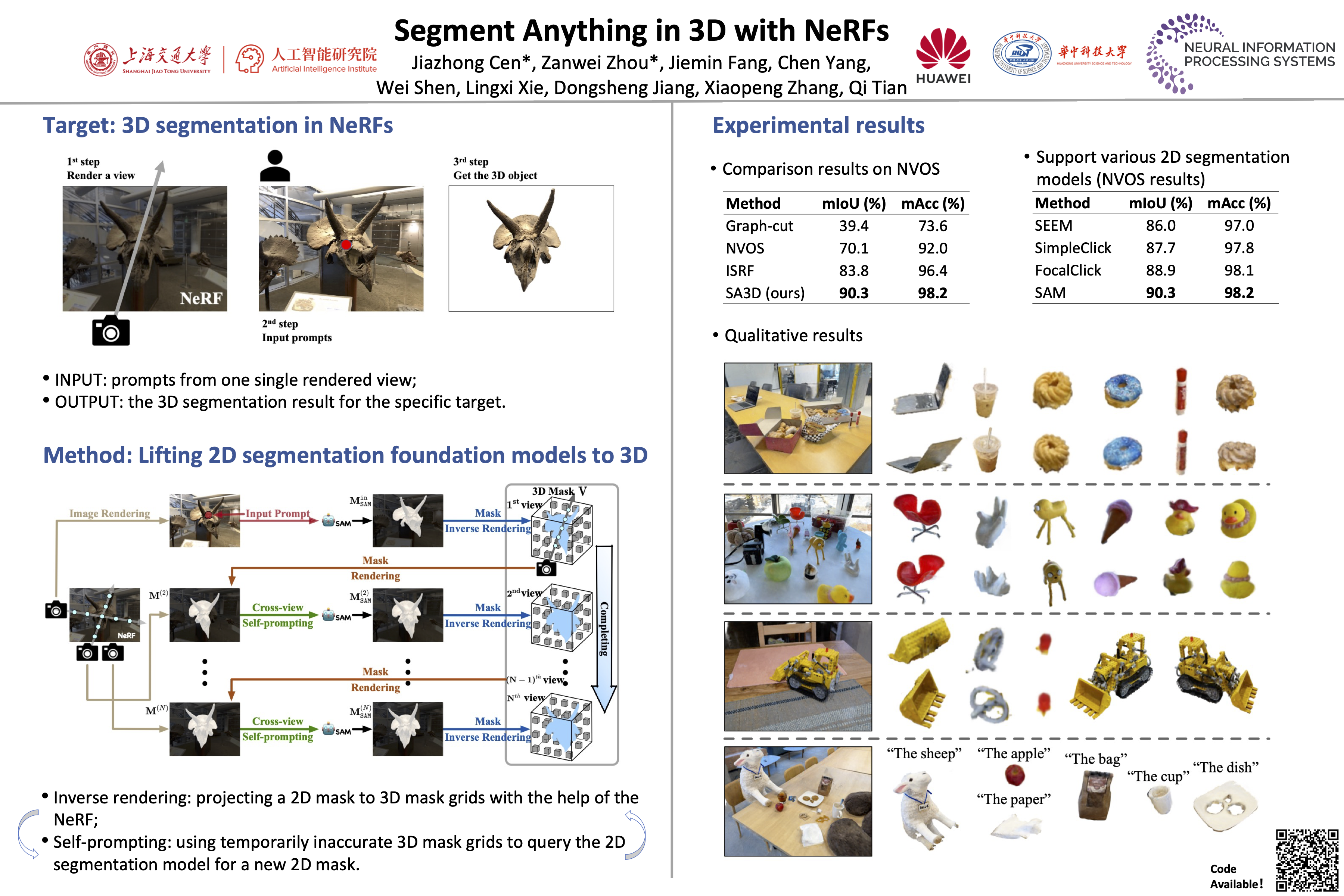
Recently, the Segment Anything Model (SAM) emerged as a powerful vision foundation model which is capable to segment anything in 2D images. This paper aims to generalize SAM to segment 3D objects. Rather than replicating the data acquisition and annotation procedure which is costly in 3D, we design an efficient solution, leveraging the Neural Radiance Field (NeRF) as a cheap and off-the-shelf prior that connects multi-view 2D images to the 3D space. We refer to the proposed solution as SA3D, for Segment Anything in 3D. It is only required to provide a manual segmentation prompt (e.g., rough points) for the target object in a single view, which is used to generate its 2D mask in this view with SAM. Next, SA3D alternately performs mask inverse rendering and cross-view self-prompting across various views to iteratively complete the 3D mask of the target object constructed with voxel grids. The former projects the 2D mask obtained by SAM in the current view onto 3D mask with guidance of the density distribution learned by the NeRF; The latter extracts reliable prompts automatically as the input to SAM from the NeRF-rendered 2D mask in another view. We show in experiments that SA3D adapts to various scenes and achieves 3D segmentation within minutes. Our research offers a generic and efficient methodology to lift a 2D vision foundation model to 3D, as long as the 2D model can steadily address promptable segmentation across multiple views.