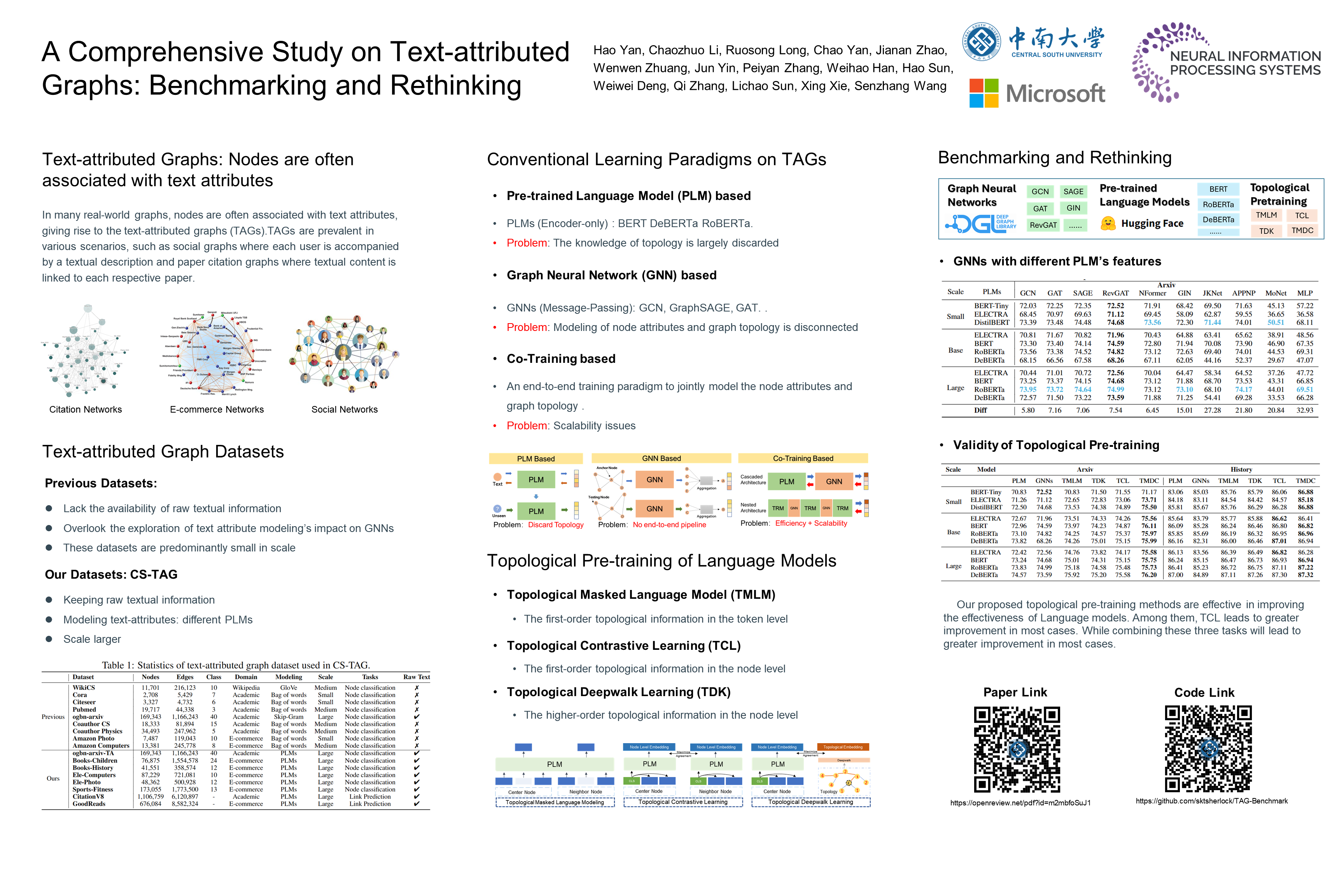
A Comprehensive Study on Text-attributed Graphs: Benchmarking and Rethinking
{kind=link}
Abstract
Text-attributed graphs (TAGs) are prevalent in various real-world scenarios, where each node is associated with a text description. The cornerstone of representation learning on TAGs lies in the seamless integration of textual semantics within individual nodes and the topological connections across nodes. Recent advancements in pre-trained language models (PLMs) and graph neural networks (GNNs) have facilitated effective learning on TAGs, garnering increased research interest. However, the absence of meaningful benchmark datasets and standardized evaluation procedures for TAGs has impeded progress in this field. In this paper, we propose CS-TAG, a comprehensive and diverse collection of challenging benchmark datasets for TAGs. The CS-TAG datasets are notably large in scale and encompass a wide range of domains, spanning from citation networks to purchase graphs. In addition to building the datasets, we conduct extensive benchmark experiments over CS-TAG with various learning paradigms, including PLMs, GNNs, PLM-GNN co-training methods, and the proposed novel topological pre-training of language models. In a nutshell, we provide an overview of the CS-TAG datasets, standardized evaluation procedures, and present baseline experiments. The entire CS-TAG project is publicly accessible at \url{https://github.com/sktsherlock/TAG-Benchmark}.