Exploring Ego-Exo View-Invariant Temporal Understanding in Video LLMs
in
Workshop: Multimodal Algorithmic Reasoning Workshop
{kind=link}
Abstract
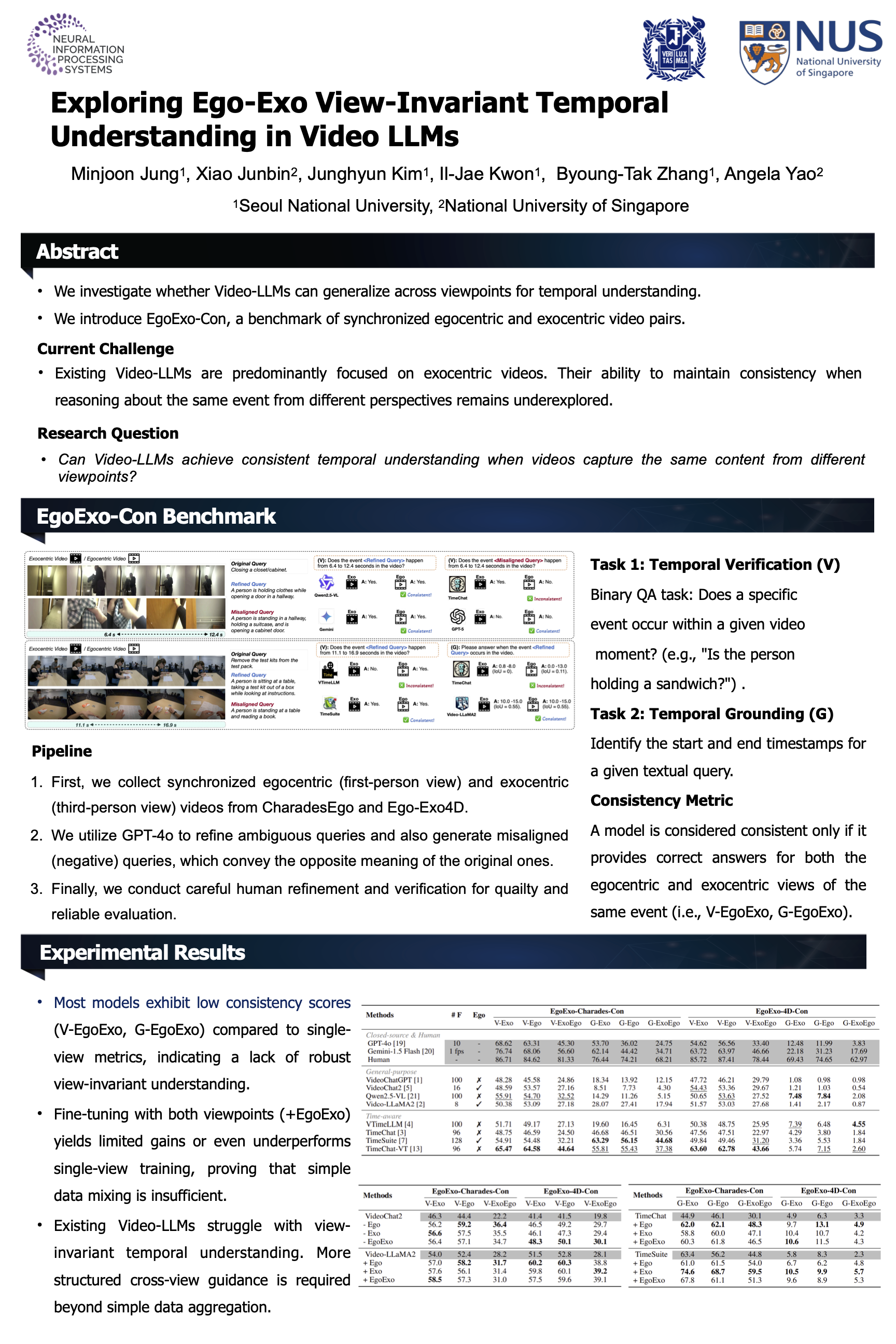
Video large language models (Video-LLMs) have shown promising video understanding capabilities. However, their ability to generalize across different viewpoints is largely underexplored. Can Video-LLMs achieve consistent temporal understanding when videos capture the same content from different viewpoints? To answer this question, we introduce EgoExo-Con (consistency), a benchmark of comprehensively synchronized egocentric and exocentric video pairs with human-refined queries. It covers two temporal understanding tasks, temporal verification and temporal grounding, and evaluates not only correctness but also consistency across viewpoints. Our result reveals that most models struggle to maintain consistency, with performance varying across video lengths, video domains, and tasks. Even when trained with both viewpoints, they show limited gains in consistency and even underperform those trained on a single view, highlighting the challenge of view-invariant video understanding.