A Differentiable Simulator for Human Vocal Learning
{kind=link}
Abstract
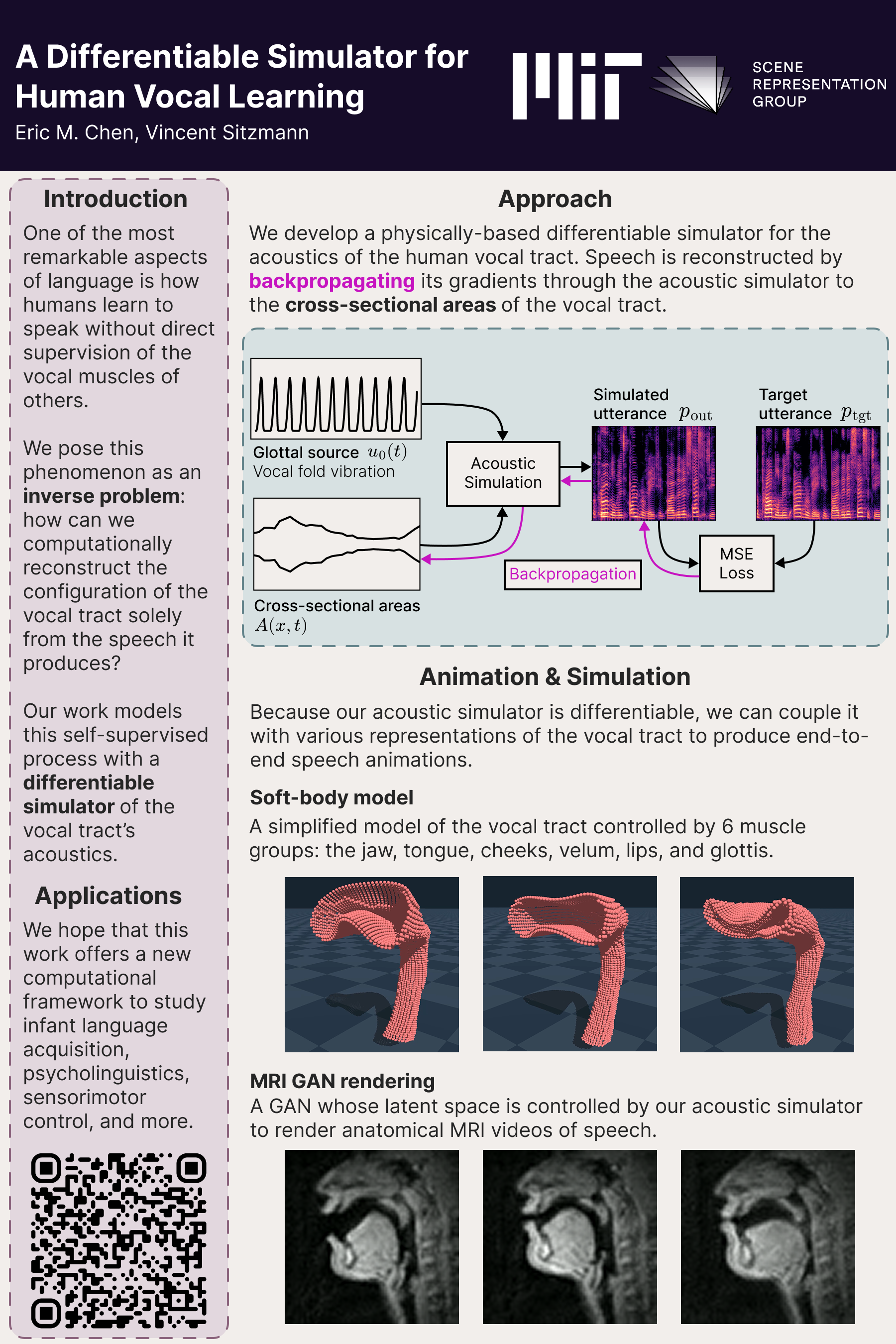
Speech is a complex sensorimotor process that requires the coordination of hundreds of muscles, yet is something we humans do almost unconsciously. Although forward models of how the vocal tract maps to speech have been studied for almost a century, the inverse process---reconstructing the dynamic vocal tract shape from its radiated speech---remains a challenge. Prior work which attempt to model the inverse process with acoustic simulation rely on sampling, which is inefficient due to the high dimensionality of the search space. To overcome this problem, we propose to model speech production with a differentiable simulator, which directly couples the vocal tract geometry and its acoustic output with analytic gradients, thereby efficiently modeling both the forward and inverse processes. Experiments show that our simulator can reconstruct human-like speech, enabling potential applications in vocal learning, psycholinguistics, and cognitive science.