Evaluating Foundation Models' 3D Understanding Through Multi-View Correspondence Analysis
Valentina Lilova ⋅ Toyesh Chakravorty ⋅ Julian I. Bibo ⋅ Emma Boccaletti ⋅ Brandon li ⋅ Lívia Baxová ⋅ Cees Snoek ⋅ Mohammadreza Salehi
{kind=link}
Abstract
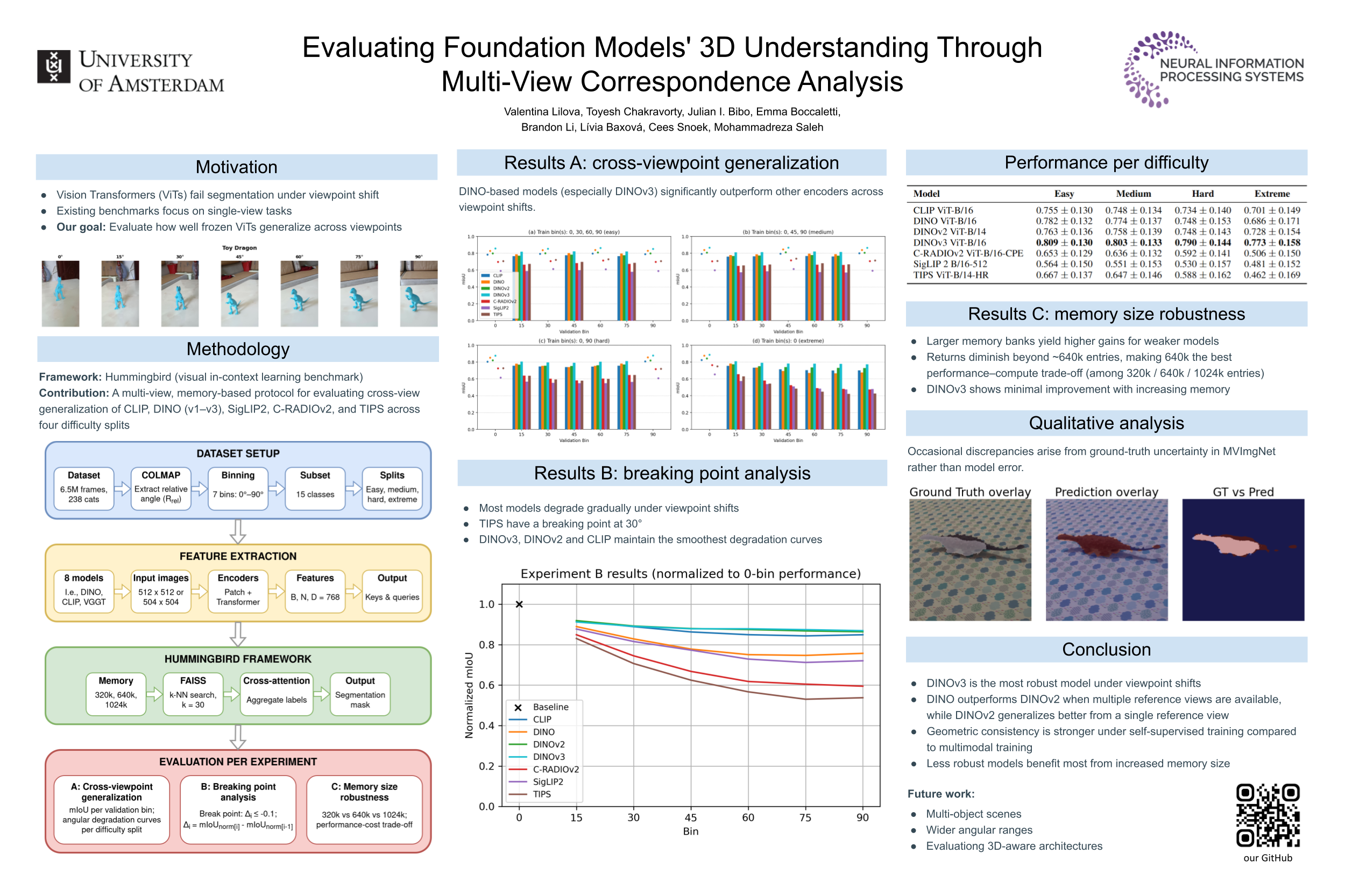
This paper extends the Hummingbird framework with the Multi-View ImageNet (MVImgNet) dataset to evaluate how foundation model image encoders handle in-context object segmentation under unseen camera angles.We group MVImgNet object views and construct memory banks from selected viewpoints.We assess generalization by evaluating performance on held-out angles.Across six pretrained Vision Transformer (ViT) models—CLIP, DINO, DINOv2, SigLIP2, C-RADIOv2, and TIPS—we find that DINO-based models perform best: DINO leads when more context viewpoints are available, while DINOv2 is strongest with fewer reference views.These results highlight the benefits of contrastive pretraining for robust performance across large viewpoint shifts.
Chat is not available.
Successful Page Load