LibriBrain: Over 50 Hours of Within-Subject MEG to Improve Speech Decoding Methods at Scale
Miran Özdogan ⋅ Gilad Landau ⋅ Gereon Elvers ⋅ Dulhan Jayalath ⋅ Pratik Somaiya ⋅ Francesco Mantegna ⋅ Mark Woolrich ⋅ Oiwi Parker Jones
2025 Poster
{kind=link}
Abstract
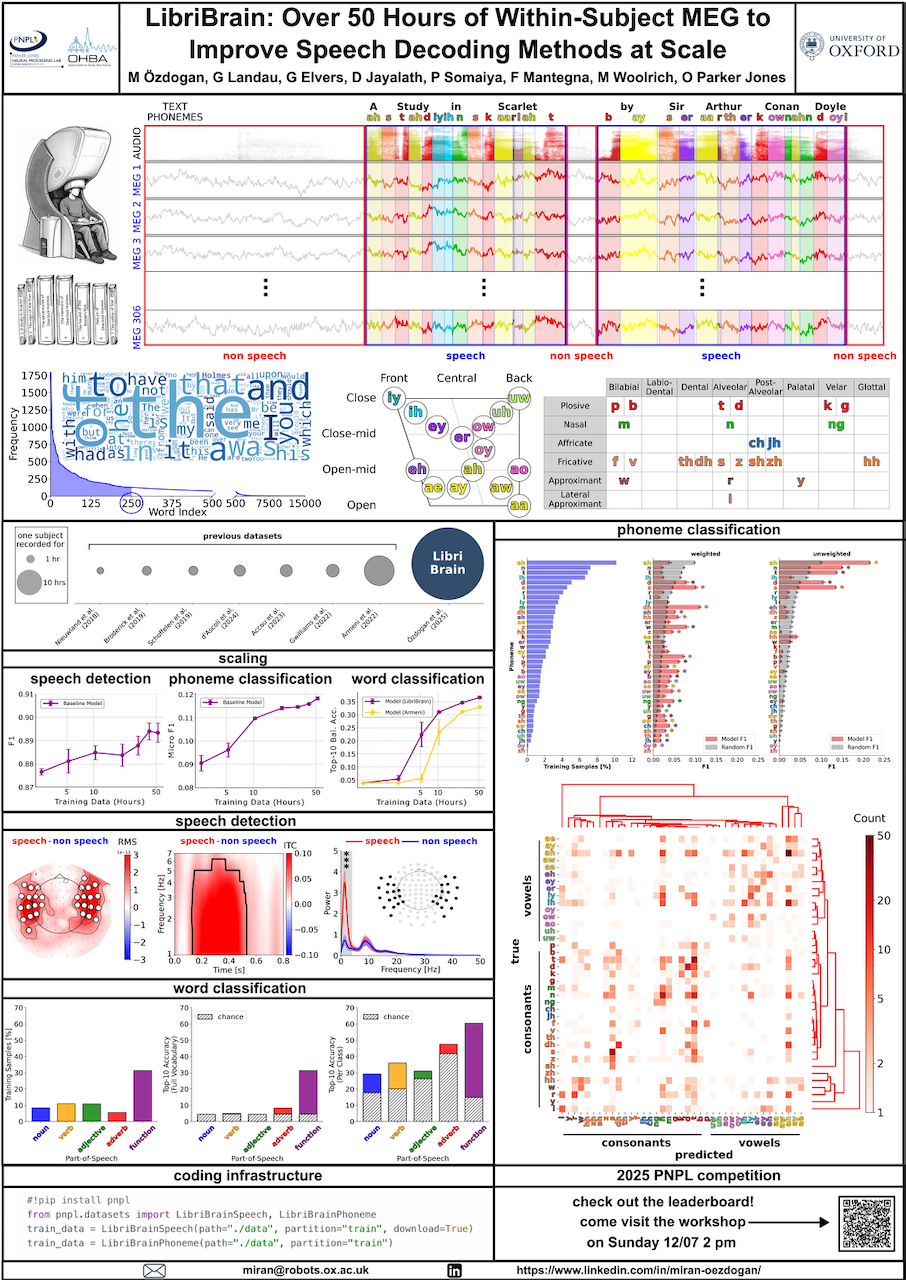
LibriBrain represents the largest single-subject MEG dataset to date for speech decoding, with over 50 hours of recordings---5$\times$ larger than the next comparable dataset and 50$\times$ larger than most. This unprecedented `depth' of within-subject data enables exploration of neural representations at a scale previously unavailable with non-invasive methods. LibriBrain comprises high-quality MEG recordings together with detailed annotations from a single participant listening to naturalistic spoken English, covering nearly the full Sherlock Holmes canon. Designed to support advances in neural decoding, LibriBrain comes with a Python library for streamlined integration with deep learning frameworks, standard data splits for reproducibility, and baseline results for three foundational decoding tasks: speech detection, phoneme classification, and word classification. Baseline experiments demonstrate that increasing training data yields substantial improvements in decoding performance, highlighting the value of scaling up deep, within-subject datasets. By releasing this dataset, we aim to empower the research community to advance speech decoding methodologies and accelerate the development of safe, effective clinical brain-computer interfaces.
Video
Chat is not available.
Successful Page Load