HARDMath2: A Benchmark for Applied Mathematics Built by Students as Part of a Graduate Class
James Roggeveen ⋅ Erik Wang ⋅ David Ettel ⋅ Will Flintoft ⋅ Peter Donets ⋅ Raglan Ward ⋅ Ahmed Roman ⋅ Anton Graf ⋅ Siddharth Dandavate ⋅ Ava Williamson ⋅ Felix Yeung ⋅ Kacper Migacz ⋅ Yijun Wang ⋅ Egemen Bostan ⋅ Duy Thuc Nguyen ⋅ Zhe He ⋅ Marc Descoteaux ⋅ Anne Mykland ⋅ Shida Liu ⋅ Jorge Garcia Ponce ⋅ Luke Zhu ⋅ Yuyang Chen ⋅ Ekaterina Ivshina ⋅ Miguel Fernandez ⋅ Minjae Kim ⋅ Kennan Gumbs ⋅ Matthew Tan ⋅ Russell Yang ⋅ Mai Hoang ⋅ David Brown ⋅ Isabella Silveira ⋅ Lavon Sykes ⋅ Arjun Nageswaran ⋅ William Fredenberg ⋅ Yiming Chen ⋅ Lucas Martin ⋅ Yixing Tang ⋅ Kelly Smith ⋅ Hongyu Liao ⋅ Logan Wilson ⋅ Alexander D. Cai ⋅ Lucy Nathwani ⋅ Nickholas Gutierrez ⋅ Andrea Elizabeth Biju ⋅ Michael Brenner
2025 Poster
{kind=link}
Abstract
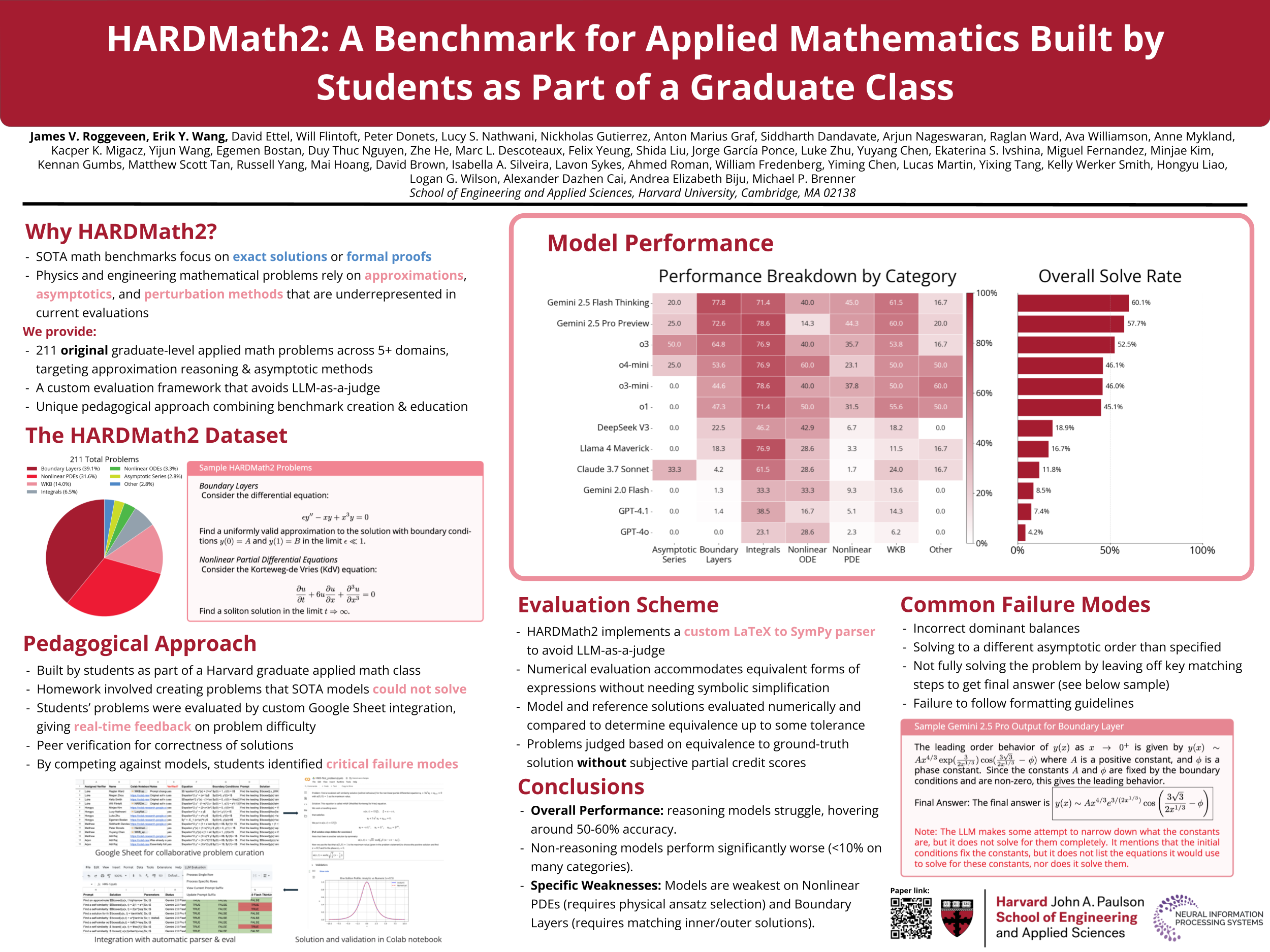
Large language models (LLMs) have shown remarkable progress in mathematical problem-solving, but evaluation has largely focused on problems that have exact analytical solutions or involve formal proofs, often overlooking approximation-based problems ubiquitous in applied science and engineering. To fill this gap, we build on prior work and present $\textbf{HARDMath2}$, a dataset of 211 original problems covering the core topics in an introductory graduate applied math class, including boundary-layer analysis, WKB methods, asymptotic solutions of nonlinear partial differential equations, and the asymptotics of oscillatory integrals. This dataset was designed and verified by the students and instructors of a core graduate applied mathematics course at Harvard. We build the dataset through a novel collaborative environment that challenges students to write and refine difficult problems consistent with the class syllabus, peer-validate solutions, test different models, and automatically check LLM-generated solutions against their own answers and numerical ground truths. Evaluation results show that leading frontier models still struggle with many of the problems in the dataset, highlighting a gap in the mathematical reasoning skills of current LLMs. Importantly, students identified strategies to create increasingly difficult problems by interacting with the models and exploiting common failure modes. This back-and-forth with the models not only resulted in a richer and more challenging benchmark but also led to qualitative improvements in the students' understanding of the course material, which is increasingly important as we enter an age where state-of-the-art language models can solve many challenging problems across a wide domain of fields.
Video
Chat is not available.
Successful Page Load