NeurIPS 2021 Competition Track
Below you will find a brief summary of accepted competitions NeurIPS 2021. Regular competitions take place before the NeurIPS, whereas live competitions will have their final phase during the competition session @NeurIPS2021.
Competitions are listed in alphabetical order, all prizes are tentative and depend solely on the organizing team of each competition and the corresponding sponsors. Please note that all information is subject to change, please visit the competition websites regularly and contact the organizers of each competition directly for more information.
NeurIPS 2021 Accepted Competitions
BASALT: A MineRL Competition on Solving Human-Judged Tasks
Rohin Shah, (UC Berkeley), Cody Wild (UC Berkeley), Steven H. Wang (UC Berkeley), Neel Alex (UC Berkeley), Brandon Houghton (OpenAI), William Guss (OpenAI), Sharada Mohanty (AIcrowd), Stephanie Milani (Carnegie Mellon University), Nicholay Topin (Carnegie Mellon University), Pieter Abbeel (UC Berkeley), Stuart Russell (UC Berkeley), Anca Dragan (UC Berkeley).
The Benchmark for Agents that Solve Almost-Lifelike Tasks (BASALT) competition aims to promote research in the area of learning from human feedback in order to enable agents that can pursue tasks that do not have crisp, easily defined reward functions. We provide tasks consisting of a simple English language description alongside a Gym environment, without any associated reward function, but with expert demos. Participants will train agents for these tasks using their preferred methods.
We expect typical solutions will use imitation learning, or learning from comparisons. Submitted agents will be evaluated based on how well they complete the tasks, as judged by humans given the same description of the tasks.
Billion-Scale Approximate Nearest Neighbor Search Challenge
Harsha Vardhan Simhadri (Microsoft Research India), George Williams (GSI Technology), Martin Aumüller (IT University of Copenhagen), Artem Babenko(Yandex), Dmitry Baranchuk (Yandex), Qi Chen (Microsoft Research Asia), Matthijs Douze (Facebook AI Research), Ravishankar Krishnaswamy (Microsoft Research India, IIT Madras), Gopal Srinivasa (Microsoft Research India), Suhas Jayaram Subramanya (Carnegie Mellon University), Jingdong Wang (Microsoft Research Asia).
Approximate Nearest Neighbor Search (ANNS) amounts to finding nearby points to a given query point in a high-dimensional vector space. ANNS algorithms optimize a tradeoff between search speed, memory usage and accuracy with respect to an exact sequential search. Thanks to efforts like ann-benchmarks.com, the state of the art for ANNS on million-scale datasets is quite clear. This competition aims at pushing the scale to out-of-memory billion-scale datasets and other hardware configurations that are realistic in many current applications. The competition uses six representative billion-scale datasets -- many newly released for this competition -- with their associated accuracy metrics. There are three tracks depending on hardware settings: (T1) limited memory (T2) limited main memory + SSD (T3) any hardware configuration including accelerators and custom silicon. We will use two recent indexing algorithms, DiskANN and FAISS, as baselines for tracks T1 and T2. The anticipated impact is an understanding of the ideas that apply at a billion-point scale, bridging communities that work on ANNS problems, and a platform for newer researchers to contribute and develop this relatively new research area. We will provide Azure cloud compute credit to participants with promising ideas without necessary infrastructure to develop their submissions.
Diamond: A MineRL Competition on Training Sample-Efficient Agents
William Guss (OpenAI Inc., Carnegie Mellon University), Alara Dirik (Bogazici University), Byron Galbraith (Talla), Brandon Houghton (OpenAI Inc.), Anssi Kanervisto (University of Eastern Finland), Noboru Kuno (Microsoft Research), Stephanie Milani (Carnegie Mellon University), Sharada Mohanty (AICrowd), Karolis Ramanauskas ( N/A ), Ruslan Salakhutdinov (Carnegie Mellon University), Rohin Shah (UC Berkeley ), Nicholay Topin (Carnegie Mellon University), Steven Wang (UC Berkeley ), Cody Wild (UC Berkeley).
Enhanced Zero-Resource Speech Challenge 2021: Language Modelling from Speech and Images
Ewan Dunbar (University of Toronto), Alejandrina Cristia (École Normale Supérieure - CNRS), Okko Räsänen (Aalto University – Tampere University), Bertrand Higy (Tilburg University), Marvin Lavechin (École Normale Supérieure), Grzegorz Chrupała (Tilburg University), Afra Alishahi (Tilburg University), Chen Yu (University of Texas at Austin), Maureen de Seyssel (École Normale Supérieure - Inria), Tu Anh Nguyen (École Normale Supérieure - Inria), Mathieu Bernard (École Normale Supérieure - Inria), Nicolas Hamilakis (École Normale Supérieure - Inria), Emmanuel Dupoux (École Normale Supérieure - Inria).
Evaluating Approximate Inference in Bayesian Deep Learning
Andrew Gordon Wilson (New York University), Pavel Izmailov (New York University), Matthew D. Hoffman (Google Research), Yarin Gal (University of Oxford), Yingzhen Li (Imperial College London), Melanie F. Pradier (Microsoft Research Cambridge), Sharad Vikram (Google Research), Andrew Foong (University of Cambridge), Sanae Lotfi (New York University), Sebastian Farquhar (University of Oxford).

HEAR 2021: Holistic Evaluation of Audio Representations
Joseph Turian (unaffiliated), Jordie Shier (University of Victoria), Bhiksha Raj (Carnegie Mellon University), Björn W. Schuller (Imperial College London + University of Augsburg), Christian James Steinmetz (Queen Mary University of London), Colin Malloy (University of Victoria), George Tzanetakis (University of Victoria), Gissel Velarde (Universidad Privada Boliviana), Kirk McNally (University of Victoria), Max Henry (McGill University), Nicolas Pinto (Cygni Labs), Yonatan Bisk (Carnegie Mellon University), Gyanendra Das (Indian Institute of Technology (ISM)), Humair Raj Khan (unaffiliated), Camille Noufi (Stanford), Dorien Herremans (Singapore University of Technology and Design), Jesse Engel (Google Brain), Justin Salamon (Adobe Research), Philippe Esling (Institut de Recherche et de Coordination Acoustique/Musique), Pranay Manocha (Princeton), Shinji Watanabe (Carnegie Mellon University), Zeyu Jin (Adobe Research).

Humans can infer a wide range of properties from a perceived sound, such as information about the source (e.g. what generated the sound? where is it coming from?), the information the sound conveys (this is a word that means X, this is a musical note in scale Y), and how it compares to other sounds (these two sounds come/don't come from the same source and are/aren't identical). Can any one learned representation do the same? The aim of this competition is to develop a general-purpose audio representation that provides a meaningful basis for learning in a wide variety of tasks and scenarios. We challenge participants with the following questions: Is it possible to develop a single representation that models all psychoacoustic phenomena? What approach best generalizes to a wide range of downstream audio tasks without fine-tuning? What audio representation allows researchers to formulate and solve novel and societally-valuable problems in simple, repeatable ways? We will evaluate audio representations using a benchmark suite across a variety of domains, including speech, environmental sound, medical audio, and music. In the spirit of shared exchange, all participants must submit an audio embedding model, following a common API, that is general-purpose, open-source, and freely available to use.
IGLU: Interactive Grounded Language Understanding in a Collaborative Environment
Julia Kiseleva (Microsoft Research), Ziming Li (University of Amsterdam), Mohammad Aliannejadi (University of Amsterdam), Maartje ter Hoeve (University of Amsterdam), Mikhail Burtsev (MIPT — Moscow Institute of Physics and Technology), Alexey Skrynnik (MIPT — Moscow Institute of Physics and Technology, Artem Zholus(MIPT — Moscow Institute of Physics and Technology), Aleksandr Panov (MIPT — Moscow Institute of Physics and Technology), Katja Hofmann (Microsoft Research), Kavya Srinet (Facebook AI), Arthur Szlam (Facebook AI), Michel Galley (Microsoft Research), Ahmed Awadallah (Microsoft Research)

Human intelligence has the remarkable ability to quickly adapt to new tasks and environments. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose IGLU: Interactive Grounded Language Understanding in a Collaborative Environment. The primary goal of the competition is to approach the problem of how to build interactive agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants.
Image similarity challenge
Matthijs Douze (Facebook AI), Cristian Canton Ferrer (Facebook AI), Zoë Papakipos (Facebook AI), Lowik Chanussot (Facebook AI), Giorgos Tolias (Czech Technical University), Filip Radenovic (Facebook AI), Ondřej Chum (Czech Technical University).

Matching images by similarity consists in identifying the source of an altered image in a large collection of unrelated images. This technology is applied to a range of content moderation domains: misinformation, copyright infringement, scams, etc.
In these domains, it has concrete and real-world impact to protect the integrity of persons engaging in social media. This challenge aims at compiling a dataset focused on image similarity in order to provide a benchmark of efforts from academic researchers and industrial actors. The participants will be provided with a reference collection of one million images and a set of query images. The query images are transformed versions of reference images. The transformations include various types of image edition, collages, and re-encoding. The participants are tasked with finding the source image from the dataset. Baseline methods include all techniques from the instance matching literature (keypoint matching, global descriptor extraction). The anticipated scientific impact is to bring back image similarity detection as an important and challenging task in the computer vision domain and refresh the state of the art. Participants could adopt, for example, recent approaches from self-supervised learning.
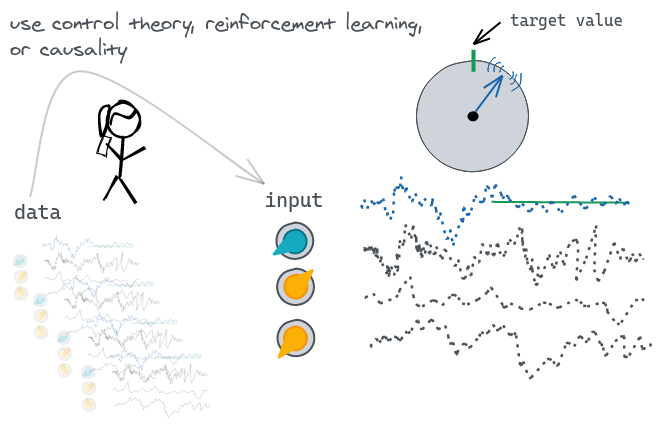
Learning By Doing: Controlling a Dynamical System using Control Theory, Reinforcement Learning, or Causality
Sebastian Weichwald* (University of Copenhagen), Niklas Pfister* (University of Copenhagen), Dominik Baumann (RWTH Aachen University), Isabelle Guyon (Université Paris-Saclay, ChaLearn), Oliver Kroemer (Carnegie Mellon University), Tabitha Edith Lee (Carnegie Mellon University), Søren Wengel Mogensen (Lund University), Jonas Peters (University of Copenhagen), Sebastian Trimpe (RWTH Aachen University).
Machine Learning for Combinatorial Optimization
Simon Bowly (Monash University), Quentin Cappart (Polytechnique Montréal), Jonas Charfreitag (University of Bonn), Laurent Charlin (HEC Montréal), Didier Chételat (Polytechnique Montréal), Antonia Chmiela (Zuse Institute Berlin), Justin Dumouchelle (Polytechnique Montréal), Maxime Gasse (Polytechnique Montréal), Ambros Gleixner (Zuse Institute Berlin), Aleksandr M. Kazachkov (University of Florida), Elias B. Khalil (University of Toronto), Pawel Lichocki (Google), Andrea Lodi (Polytechnique Montréal), Miles Lubin (Google), Chris J. Maddison (University of Toronto), Christopher Morris (Polytechnique Montréal), Augustin Parjadis (Polytechnique Montréal), Dimitri J. Papageorgiou (ExxonMobil), Sebastian Pokutta (Zuse Institute Berlin), Antoine Prouvost (Polytechnique Montréal), Lara Scavuzzo (TU Delft), Giulia Zarpellon (University of Toronto).

The Machine Learning for Combinatorial Optimization (ML4CO) competition aims at improving a state-of-the-art mathematical solver by replacing key heuristic components with machine learning models trained on historical data. To that end participants will compete on the three following challenges, each corresponding to a distinct control task arising in a branch-and-bound solver: producing good solutions (primal task), proving optimality via branching (dual task), and choosing the best solver parameters (configuration task). Each task is exposed through an OpenAI-gym Python API build on top of the open-source solver SCIP, using the Ecole library. Participants can compete in any subset of the proposed challenges. While we encourage solutions derived from the reinforcement learning paradigm, any algorithmic solution respecting the competition's API is accepted.
MetaDL: Few Shot Learning Competition with Novel Datasets from Practical Domains
Adrian El Baz (ChaLearn, USA), Isabelle Guyon (ISN/INRIA/CNRS, Université Paris-Saclay, France, and ChaLearn, USA), Zhengying Liu (LISN/INRIA/CNRS, Université Paris-Saclay, France), Jan N. van Rijn (Leiden University, the Netherlands), Haozhe Sun (LISN/INRIACNRS, Université Paris-Saclay, France), Sebastien Treguer (ISN/INRIA/CNRS, Université Paris-Saclay, France, and ChaLearn, USA), Wei-Wei Tu (4Paradigm Inc., China and ChaLearn, USA), Ihsan Ullah (Université Paris-Saclay, France), Joaquin Vanschoren (TU Eindhoven, the Netherlands)

The competition consists of novel datasets from various domains, including healthcare, ecology, biology, and chemistry. The competition will consist of three phases: a public phase, a feedback phase, and a final phase. The last two phases will be run with code submissions, fully bind-tested on the Codalab challenge platform. A single (final) submission will be evaluated during the final phase, using five fresh datasets, currently unknown to the meta-learning community.
Multimodal Single-Cell Data Integration
Daniel Burkhardt (Cellarity), Smita Krishnaswamy (Yale University), Malte Luecken (Helmholtz Zentrum München), Debora Marks (Harvard Medical School), Angela Pisco (Chan Zuckerberg Biohub), Bastian Rieck (ETH Zürich), Jian Tang (HEC Montreal), Fabian Theis (Helmholtz Zentrum München), Alexander Tong (Yale University), and Guy Wolf (Université de Montréal).

Scaling from a dozen cells a decade ago to millions of cells today, single-cell measurement technologies are driving a revolution in the life sciences. Recent advances make it possible to measure multiple high-dimensional modalities (e.g. DNA accessibility, RNA, and proteins) simultaneously in the same cell. This data provides, for the first time, a direct and comprehensive view into the layers of gene regulation that drive biological diversity and disease. In this competition, we present three critical tasks on multimodal single-cell data using public datasets and a first-of-its-kind multi-omics benchmarking dataset. Teams will predict one modality from another and learn representations of multiple modalities measured in the same cells. Progress will elucidate how a common genetic blueprint gives rise to distinct cell types and processes, as a foundation for improving human health.
Open Catalyst Challenge
Abhishek Das (Facebook AI Research), Muhammed Shuaibi (Carnegie Mellon University), Siddharth Goyal (Facebook AI Research), Adeesh Kolluru (Carnegie Mellon University), Janice Lan (Facebook AI Research), Aini Palizhati (Carnegie Mellon University), Anuroop Sriram (Facebook AI Research), Brandon Wood (National Energy Research Scientific Computing Center), Aditya Grover (Facebook AI Research), Devi Parikh (Facebook AI Research, Georgia Tech), Zachary Ulissi (Carnegie Mellon University), C. Lawrence Zitnick (Facebook AI Research).

The Open Catalyst Challenge invites participants to submit results of machine learning models that simulate the interaction of a molecule on a catalyst's surface. ML models may either directly predict the relaxed state atomic configuration of the entire molecule + catalyst system, or iteratively predict and integrate per-atom forces to simulate how atoms will move around starting from an arbitrary initial state. By predicting this interaction accurately, the catalyst's impact on the overall rate of a chemical reaction may be estimated; a key factor in filtering potential catalysis materials and addressing the world’s energy needs.
The Open Catalyst Project is a collaborative research effort between Facebook AI Research (FAIR) and Carnegie Mellon University’s (CMU) Department of Chemical Engineering. The aim is to use AI to model and discover new catalysts for use in renewable energy storage to help in addressing climate change.
Real Robot Challenge II
Stefan Bauer, (MPI for Intelligent Systems), Joel Akpo (MPI for Intelligent Systems), Manuel Wüthrich (RR-Learning), Rosemary Nan Ke (MILA, Deepmind), Anirudh Goyal (MILA), Thomas Steinbrenner (MPI for Intelligent Systems), Felix Widmaier (MPI for Intelligent Systems), Annika Buchholz (MPI for Intelligent Systems), Bernhard Schölkopf (MPI for Intelligent Systems), Dieter Büchler (MPI for Intelligent Systems), Ludovic Righetti (NYU), Franziska Meier (Facebook).

Reconnaissance Blind Chess
Ryan W. Gardner (Johns Hopkins University Applied Physics Laboratory - JHU/APL), Gino Perrotta, Corey Lowman (JHU/APL), Casey Richardson (JHU/APL), Andrew Newman (JHU/APL), Jared Markowitz (JHU/APL), Nathan Drenkow (JHU/APL), Barton Paulhamus (JHU/APL), Ashley J. Llorens (Microsoft Research), Todd W. Neller (Gettysburg College) Raman Arora (Johns Hopkins University), Bo Li (University of Illinois), Mykel J. Kochenderfer (Stanford University).

Reconnaissance Blind Chess is like chess except a player cannot see her opponent's pieces in general. Rather, each player chooses a 3x3 square of the board to privately observe each turn. Algorithms used to create agents for previous games like chess, Go, and poker break down in Reconnaissance Blind Chess for several reasons including the imperfect information, absence of obvious abstractions, and lack of common knowledge. In addition to this NeurIPS competition, the game is recently part of the new Hidden Information Games Competition (HIGC) that is organized with the AAAI Reinforcement Learning in Games workshop (2022). Build the best bot for this challenge in making strong decisions in multi-agent scenarios in the face of uncertainty.
Shifts Challenge: Robustness and Uncertainty under Real-World Distributional Shift
Andrey Malinin (Yandex, HSE), Neil Band (University of Oxford), German Chesnokov (Yandex), Yarin Gal (University of Oxford, Alan Turing Institute), Alexander Ganshin (Yandex), Mark J. F. Gales (University of Cambridge), Alexey Noskov (Yandex), Andrey Ploskonosov (Yandex), Liudmila Prokhorenkova (Yandex, HSE, MIPT), Mariya Shmatova (Yandex), Vyas Raina (University of Cambridge), Vatsal Raina (University of Cambridge), Denis Roginskii (Yandex), Panos Tigas (University of Oxford), Boris Yangel (Yandex).

Mismatch between training and deployment data, known as distributional shift, adversely impacts ML models and is ubiquitous in real, industrial applications. In this competition the contestants’ goal is to develop models which are both robust to distributional shift and can detect it via uncertainty estimation. The broad aim of this competition is to raise awareness of the issue and stimulate the community to work on tasks and modalities taken from large-scale industrial applications. Thus, we provide the "Shifts Dataset" - a new, large dataset of genuine `in the wild' examples of distributional shift from weather prediction, machine translation, and vehicle motion prediction. Each task represents a particular data-modality and is uniquely challenging. Each task will have an associated competition track with prizes for top contestants.
The AI Driving Olympics
Andrea Censi (ETH Zurich), Liam Paull (University of Montreal), Jacopo Tani (ETH Zurich), Emilio Frazzoli (ETH Zurich), Holger Caesar (Motional), Matthew R. Walter (TTIC), Andrea F. Daniele (TTIC), Sahika Genc (Amazon), Sharada Mohanty (AICrowd).

The AI Driving Olympics (AI-DO) is a series of embodied intelligence competitions in the field of autonomous vehicles. The overall objective of AI-DO is to provide accessible mechanisms for benchmarking progress in autonomy applied to the task of autonomous driving. This edition of the AI-DO features three different leagues: (a) urban driving, based on the Duckietown platform; (b) advanced perception, based on the Motional nuScenes dataset; and (c) racing, based on the AWS Deepracer platform. Each league has several “challenges" with independent leaderboards. The urban driving and racing leagues include embodied tasks, where agents are deployed on physical robots in addition to simulation.
The NetHack Challenge
Eric Hambro (Facebook AI Research); Sharada Mohanty (AICrowd); Dipam Chakrabroty (AIcrowd); Edward Grefenstette (Facebook AI Research); Minqi Jiang (Facebook AI Research & University College London); Robert Kirk (University College London); Vitaly Kurin (University of Oxford); Heinrich Küttler (Facebook AI Research); Vegard Mella (Facebook); Nantas Nardelli (University of Oxford); Jack Parker-Holder (University of Oxford); Roberta Raileanu (NYU); Tim Rocktäschel (Facebook AI Research & University College London); Danielle Rothermel (Facebook); Mikayel Samvelyan (University College London & Facebook AI Research).

The NetHack Challenge is based on the NetHack Learning Environment (NLE), where teams will compete to build the best agents to play the game of NetHack. NetHack is a ASCII-rendered single-player dungeon crawl game that is one of the oldest and most difficult computer games in history. NetHack is procedurally-generated, with hundreds of different entities and complex environment dynamics, presenting an extremely challenging environment for both current state-of-the-art RL agents and humans, while crucially being lightning-fast to simulate. We are excited that this competition offers machine learning students, researchers and NetHack-bot builders the opportunity to participate in a grand challenge in AI without prohibitive computational costs—and we are eagerly looking forward to the wide variety of submissions.
The NeurIPS 2021 BEETL Competition: Benchmarks for EEG Transfer Learning
Xiaoxi Wei (Imperial College London); Vinay Jayaram (Facebook Reality Labs); Sylvain Chevallier (University of Versailles); Giulia Luise (Imperial College London); Camille Jeunet (University of Bordeaux); Moritz Grosse-Wentrup (University of Vienna): Alexandre Gramfort (INRIA & Université Paris-Saclay); A. Aldo Faisal (Imperial College London).

The Benchmarks for EEG Transfer Learning (BEETL) is a competition that aims to stimulate the development of transfer and meta-learning algorithms applied to a prime example of what makes the use of biosignal data hard, EEG data. BEETL acts as a much-needed benchmark for domain adaptation algorithms in EEG decoding and provides a real-world stimulus goal for transfer learning and meta-learning developments for both academia and industry. Given the multitude of different EEG-based algorithms that exist, we offer two specific challenges: Task 1 is a cross-subject sleep stage decoding challenge reflecting the need for transfer learning in clinical diagnostics, and Task 2 is a cross-dataset motor imagery decoding challenge reflecting the need for transfer learning in human interfacing.
Traffic4cast 2021 – Temporal and Spatial Few-Shot Transfer Learning in Traffic Map Movie Forecasting
Moritz Neun (HERE Technologies, IARAI - Institute of Advanced Research in Artificial Intelligence Vienna (Austria)), Christian Eichenberger (IARAI), Henry Martin (ETH Zürich (Switzerland), IARAI), Pedro Herruzo (Polytechnic University of Catalonia (Spain), IARAI), David Jonietz (HERE Technologies), Daniel Springer (IARAI), Markus Spanring (IARAI), Avi Avidan (IARAI), Luis Ferro (IARAI), Fei Tang (HERE Technologies), Ali Soleymani (HERE Technologies), Rohit Gupta (HERE Technologies), Bo Xu (HERE Technologies), Kevin Malm, (HERE Technologies), Aleksandra Gruca (Silesian University of Technology Warsaw (Poland), IARAI), Johannes Brandstetter (The Amsterdam Machine Learning Lab (AMLab), Johannes Kepler University Linz (Austria), IARAI), Michael Kopp (HERE Technologies, IARAI), David P. Kreil (IARAI), Sepp Hochreiter (Johannes Kepler University Linz (Austria), IARAI).

VisDA21: Visual Domain Adaptation
Kate Saenko (BU & MIT-IBM Watson AI), Kuniaki Saito (BU), Donghyun Kim (BU), Samarth Mishra (BU), Ben Usman (BU), Piotr Teterwak (BU), Dina Bashkirova (BU), Dan Hendrycks (UC Berkeley).

Progress in machine learning is typically measured by training and testing a model on the same distribution of data, i.e., the same domain. However, in real world applications, models often encounter out-of-distribution data. The VisDA21 competition invites methods that can adapt to novel test distributions and handle distributional shifts. Our task is object classification, but we measure accuracy on novel domains, rather than the traditional in-domain benchmarking. Teams will be given labeled source data and unlabeled target data from a different distribution (such as novel viewpoints, backgrounds, image quality). In addition, the target data may have missing and/or novel classes. Successful approaches will improve classification accuracy of known categories on target-domain data while learning to deal with missing and/or unknown categories.
WebQA Competition
Yingshan Chang (LTI@CMU), Yonatan Bisk (LTI@CMU), Mridu Narang (Microsoft), Jared Fernandez (LTI@CMU), Levi Melnick (Microsoft), Guihong Cao (Microsoft), Hisami Suzuki (Microsoft), Jianfeng Gao (Microsoft)

WebQA is a new benchmark for multimodal multihop reasoning in which systems are presented with the same style of data as humans when searching the web: snippets and images. Upon seeing a question, the system must identify which candidates potentially inform the answer from a candidate pool. Then the system is expected to aggregate information from selected candidates with reasoning to generate an answer in natural language form. Each datum is a question paired with a series of potentially long snippets or images that serve as "knowledge carriers" over which to reason. Systems will be evaluated on both supporting fact retrieval and answer generation to measure correctness and interpretability. To demonstrate multihop multimodal reasoning ability, models should be able to 1) understand and represent knowledge from different modalities, 2) identify and aggregate relevant knowledge fragments scattered across multiple sources, 3) make inference and do natural language generation.
Program committee
We are very grateful to the colleagues that helped us reviewing and selecting the competition proposals for this year:
Alexander I. Rudnicky (Carnegie Mellon University)
Antoine Marot (RTE France)
Aravind Mohan (Facebook)
Bogdan Emanuel Ionescu (University Politehnica of Bucharest)
Candace Ross (Massachusetts Institute of Technology)
Cecile Germain (Université Paris Sud)
Chiara Plizzari (Politecnico di Torino)
David Kreil
David Rousseau (IJCLab-Orsay)
Emilio Cartoni (Institute of Cognitive Sciences and Technologies )
Ethan Perez (New York University)
Evelyne Viegas (Microsoft Research)
Florian Laurent
Gino Perrotta (The George Washington University)
Gregory Clark (Google)
Hamed Firooz (Facebook)
Heather Gray (Lawrence Berkeley National Lab)
Hsueh-Cheng (Nick) Wang (National Chiao Tung University)
Hugo Jair Escalante (INAOE)
Isabelle Guyon (CNRS, INRIA, University Paris-Saclay and ChaLearn)
Jakob Foerster (University of Toronto)
Jared Markowitz (Johns Hopkins University Applied Physics Laboratory)
jean-roch vlimant (California Institute of Technology)
Jochen Triesch (Frankfurt Institute for Advanced Studies)
José Hernández-Orallo (Universitat Politècnica de València)
Julian Zilly (ETH Zürich)
Keiko Nagami
Kurt Shuster (Facebook)
Lino A Rodriguez Coayahuitl (INAOE)
Marco Cannici (Politecnico di Milano)
Marco Gallieri (NNAISENSE)
Mark Jordan (SRC Technologies)
Matthew Crosby (Imperial College London)
Matthias Bruhns (University of Tübingen)
Michael Noukhovitch (Mila, Universite de Montreal)
Mikhail Burtsev (MIPT)
Mikhail Hushchyn (NRU HSE)
Nicholay Topin (Machine Learning Department, Carnegie Mellon University)
Noboru Kuno (Microsoft Research)
Odd Erik Gundersen (Norwegian University of Science and Technology)
Oliver Bent (IBM Research)
Robert Perrotta (Independent)
Ron Bekkerman
Ryan W Gardner (Johns Hopkins University Applied Physics Laboratory)
Sai Vemprala (Microsoft)
Sekou L Remy (IBM Research)
Sergio Escalera (Computer Vision Center (UAB) & University of Barcelona)
Sewon Min (University of Washington)
Sharada Mohanty (AICrowd)
Stephanie Milani (Carnegie Mellon University)
Tathagata Chakraborti (IBM Research AI)
Tim Taubner (ETH)
Timothy Highley (La Salle University)
Tom Kwiatkowski (Google)
Valentin Malykh (MIPT)
Wei Zhan (University of California, Berkeley)
Zhen Xu (4Paradigm)
Zhengying Liu (Inria)