NeurIPS 2023 Competition Track Program
Below you will find a brief summary of accepted competitions NeurIPS 2023.
Competitions are grouped by category, all prizes are tentative and depend solely on the organizing team of each competition and the corresponding sponsors. Please note that all information is subject to change, visit the competition websites regularly and contact the organizers of each competition directly for more information.
Special Topics in Machine Learning
NeurIPS 2023 Machine Unlearning Competition
Eleni Triantafillou (Google DeepMind), Fabian Pedregosa (Google DeepMind), Meghdad Kurmanji (University of Warwick), Kairan Zhao (University of Warwick), Gintare Karolina Dziugaite (Google DeepMind), Peter Triantafillou (University of Warwick), Ioannis Mitliagkas (Mila, University of Montreal, Google DeepMind), Vincent Dumoulin (Google DeepMind), Lisheng Sun (LRI, Université Paris Saclay), Peter Kairouz (Google Research), Julio C. S. Jacques Junior (University of Barcelona), Jun Wan (NLPR, CASIA), Sergio Escalera (CVC and University of Barcelona), Isabelle Guyon (CNRS, INRIA, University Paris-Saclay, ChaLearn, Google DeepMind)
Contact: unlearning-challenge@googlegroups.com
 We are proposing the first competition on machine unlearning, to our knowledge. Unlearning is a rapidly growing area of research that has emerged in response to one of the most significant challenges in deep learning: allowing users to exercise their right to be forgotten. This is particularly challenging in the context of deep models, which tend to memorize information from their training data, thus compromising privacy. The lack of a standardized evaluation protocol has hindered the development of unlearning, which is a relatively new area of research. Our challenge is designed to fill this need. By incentivizing the development of better unlearning algorithms, informing the community of their relative strengths and weaknesses, and unifying evaluation criteria, we expect our competition to have a significant impact. We propose a realistic scenario for unlearning face images.
We are proposing the first competition on machine unlearning, to our knowledge. Unlearning is a rapidly growing area of research that has emerged in response to one of the most significant challenges in deep learning: allowing users to exercise their right to be forgotten. This is particularly challenging in the context of deep models, which tend to memorize information from their training data, thus compromising privacy. The lack of a standardized evaluation protocol has hindered the development of unlearning, which is a relatively new area of research. Our challenge is designed to fill this need. By incentivizing the development of better unlearning algorithms, informing the community of their relative strengths and weaknesses, and unifying evaluation criteria, we expect our competition to have a significant impact. We propose a realistic scenario for unlearning face images.
Privacy Preserving Federated Learning Document VQA
Dimosthenis Karatzas (Computer Vision Center / Universitat Autonoma de Barcelona), Rubèn Tito (Computer Vision Center / Universitat Autonoma de Barcelona), Mohamed Ali Souibgui (Computer Vision Center), Khanh Nguyen (Computer Vision Center / Universitat Autonoma de Barcelona), Raouf Kerkouche (CISPA Helmholtz Center for Information Security), Kangsoo Jung (INRIA), Marlon Tobaben (University of Helsinki), Joonas Jälkö (University of Helsinki), Vincent Poulain (Yooz), Aurelie Joseph (Yooz), Ernest Valveny (Computer Vision Center / Universitat Autonoma de Barcelona), Josep Lladós (Computer Vision Center / Universitat Autonoma de Barcelona), Antti Honkela (University of Helsinki), Mario Fritz (CISPA Helmholtz Center for Information Security)
Contact: info_pfl@cvc.uab.cat
 The Privacy Preserving Federated Learning Document VQA (PFL-DocVQA) competition aims to challenge the community with developing provable private and communications efficient solutions in a federated setting, for a real-life use case: invoice processing. The competition puts forward a dataset of real invoice documents, and associated questions and answers that require information extraction and reasoning over the document images. The objective of the competition participants would be to fine tune a pre-trained, generic, state of the art Document Visual Question Answering model provided by the organisers on the new domain. The training will take place in a federated setting resembling a typical invoice processing setup. The base model is a multi-modal generative language model, and the sensitive information might be exposed through the visual and/or the textual input modality. The PFL-DocVQA competition will run in two stages following a "Blue team / Red team" scheme. In the first stage provable privacy preserving, federated learning solutions will be solicited, while in the second stage membership inference attacks will be designed against the top performing methods. We propose to run the first stage in the timeline of NeurIPS 2023. We envisage that the competition will provide a new testbed for developing and testing private federated learning methods, while at the same time it is expected to raise awareness about privacy in the document image analysis and recognition community.
The Privacy Preserving Federated Learning Document VQA (PFL-DocVQA) competition aims to challenge the community with developing provable private and communications efficient solutions in a federated setting, for a real-life use case: invoice processing. The competition puts forward a dataset of real invoice documents, and associated questions and answers that require information extraction and reasoning over the document images. The objective of the competition participants would be to fine tune a pre-trained, generic, state of the art Document Visual Question Answering model provided by the organisers on the new domain. The training will take place in a federated setting resembling a typical invoice processing setup. The base model is a multi-modal generative language model, and the sensitive information might be exposed through the visual and/or the textual input modality. The PFL-DocVQA competition will run in two stages following a "Blue team / Red team" scheme. In the first stage provable privacy preserving, federated learning solutions will be solicited, while in the second stage membership inference attacks will be designed against the top performing methods. We propose to run the first stage in the timeline of NeurIPS 2023. We envisage that the competition will provide a new testbed for developing and testing private federated learning methods, while at the same time it is expected to raise awareness about privacy in the document image analysis and recognition community.
Causal Structure Learning from Event Sequences and Prior Knowledge
Keli Zhang(Huawei Noah's Ark Lab),Ruichu Cai(Guangdong University of Technology),Kun Kuang(Zhejiang University),Jiale Zheng(Huawei Noah's Ark Lab),Marcus Kalander(Huawei Noah's Ark Lab),Junjian Ye(Huawei Noah's Ark Lab),Mengyue Yang(University College London),Quanyu Dai(Huawei Noah's Ark Lab),Lujia Pan(Huawei Noah's Ark Lab)
Contact: noahlabcausal@huawei.com
 In this competition, we are focusing on a fundamental causal challenge: participants are asked to learn the causal alarm graphs in which every node is an alarm type from observable historical alarm data together with limited prior knowledge. The challenge originates from a real-world root cause analysis (RCA) scenario in telecommunication networks. By addressing this challenge, participants will not only help operators trouble-shooting efficiently, but also advance the field of causal discovery, and contribute to our understanding of complex systems.
In this competition, we are focusing on a fundamental causal challenge: participants are asked to learn the causal alarm graphs in which every node is an alarm type from observable historical alarm data together with limited prior knowledge. The challenge originates from a real-world root cause analysis (RCA) scenario in telecommunication networks. By addressing this challenge, participants will not only help operators trouble-shooting efficiently, but also advance the field of causal discovery, and contribute to our understanding of complex systems.
Practical Vector Search Challenge 2023
Harsha Vardhan Simhadri (Microsoft Research), Martin Aumüller (IT University of Copenhagen), Dmitry Baranchuk (MSU / Yandex), Matthijs Douze (Meta AI Research), Edo Liberty (Pinecone), Amir Ingber (Pinecone), Frank Liu (Zilliz), George Williams (big-ann-benchmarks)
Contact: Slack
 We propose a competition to encourage the development of indexing data structures and search algorithms for the Approximate Nearest Neighbor (ANN) or Vector search problem in real-world scenarios. Rather than evaluating the classical uniform indexing of dense vectors, this competition proposes to focus on difficult variants of the task. Optimizing these variants is increasingly relevant as vector search becomes commonplace and the "simple" case is sufficiently well addressed. Specifically, we propose the sparse, filtered, out-of-distribution and streaming variants of ANNS.These variants require adapted search algorithms and strategies with different tradeoffs. This competition aims at being accessible to participants with modest compute resources by limiting the scale of the datasets, normalizing on limited evaluation hardware, and accepting open-source submissions to only a subset of the datasets.This competition will build on the evaluation framework https://github.com/harsha-simhadri/big-ann-benchmarks that we set up for the billion-scale ANNS challenge https://big-ann-benchmarks.com of NeurIPS 2021.
We propose a competition to encourage the development of indexing data structures and search algorithms for the Approximate Nearest Neighbor (ANN) or Vector search problem in real-world scenarios. Rather than evaluating the classical uniform indexing of dense vectors, this competition proposes to focus on difficult variants of the task. Optimizing these variants is increasingly relevant as vector search becomes commonplace and the "simple" case is sufficiently well addressed. Specifically, we propose the sparse, filtered, out-of-distribution and streaming variants of ANNS.These variants require adapted search algorithms and strategies with different tradeoffs. This competition aims at being accessible to participants with modest compute resources by limiting the scale of the datasets, normalizing on limited evaluation hardware, and accepting open-source submissions to only a subset of the datasets.This competition will build on the evaluation framework https://github.com/harsha-simhadri/big-ann-benchmarks that we set up for the billion-scale ANNS challenge https://big-ann-benchmarks.com of NeurIPS 2021.
Natural Language Processing and LLMs
NeurIPS Large Language Model Efficiency Challenge: 1 LLM + 1GPU + 1Day
Weiwei Yang (Microsoft Research), Joe Issacson (Meta), Mark Saroufim (Meta), Driss Guessous (Meta), Kaleab Kinfu (Johns Hopkins University), Anirudh Sudarshan (Meta), Christian Puhrsch (Meta), Artidoro Pagnoni (University of Washington)
Contact: https://discord.gg/pAP3HVyZFH
 Large Language Models (LLMs) have been pivotal in the recent Cambrian explosion of generative AI applications. However, existing efforts to democratize access to fine-tune and query LLMs have been largely limited by growing hardware costs required to adapt and serve these models. Enabling low cost and efficient LLM fine-tuning and inference can have significant impact on industrial and scientific applications. Here, we present a single GPU fine-tuning and inference competition. Our goal is to accelerate the development of practical software methods to reduce the costs associated with utilizing LLMs. Furthermore, by advocating for goal-oriented and infrastructure-focused evaluation frameworks that stress reproducibility, our aim is to democratize access to these methods and enhance their accessibility to the wider public.
Large Language Models (LLMs) have been pivotal in the recent Cambrian explosion of generative AI applications. However, existing efforts to democratize access to fine-tune and query LLMs have been largely limited by growing hardware costs required to adapt and serve these models. Enabling low cost and efficient LLM fine-tuning and inference can have significant impact on industrial and scientific applications. Here, we present a single GPU fine-tuning and inference competition. Our goal is to accelerate the development of practical software methods to reduce the costs associated with utilizing LLMs. Furthermore, by advocating for goal-oriented and infrastructure-focused evaluation frameworks that stress reproducibility, our aim is to democratize access to these methods and enhance their accessibility to the wider public.
TDC 2023 (LLM Edition): The Trojan Detection Challenge
Mantas Mazeika (UIUC), Andy Zou (CMU), Norman Mu (UC Berkeley), Long Phan (Center for AI Safety), Zifan Wang (Center for AI Safety), Chunru Yu (UIUC), Adam Khoja (UC Berkeley), Fengqing Jiang (University of Washington), Aidan O'Gara (USC), Zhen Xiang (UIUC), Arezoo Rajabi (University of Washington), Dan Hendrycks (UC Berkeley), Radha Poovendran (University of Washington), Bo Li (UIUC), David Forsyth (UIUC)
Contact: tdc2023-organizers@googlegroups.com
 The Trojan Detection Challenge (LLM Edition) aims to advance the understanding and development of methods for detecting hidden functionality in large language models (LLMs). The competition features two main tracks: the Trojan Detection Track and the Red Teaming Track. In the Trojan Detection Track, participants are given a large language model containing thousands of trojans and tasked with discovering the triggers for these trojans. In the Red Teaming Track, participants are challenged to elicit specific undesirable behaviors from a large language model fine-tuned to avoid those behaviors. TDC 2023 will include Base Model and Large Model subtracks to enable broader participation, and established trojan detection and red teaming baselines will be provided as a starting point. By uniting trojan detection and red teaming, TDC 2023 aims to foster collaboration between these communities to promote research on hidden functionality in LLMs and enhance the robustness and security of AI systems.
The Trojan Detection Challenge (LLM Edition) aims to advance the understanding and development of methods for detecting hidden functionality in large language models (LLMs). The competition features two main tracks: the Trojan Detection Track and the Red Teaming Track. In the Trojan Detection Track, participants are given a large language model containing thousands of trojans and tasked with discovering the triggers for these trojans. In the Red Teaming Track, participants are challenged to elicit specific undesirable behaviors from a large language model fine-tuned to avoid those behaviors. TDC 2023 will include Base Model and Large Model subtracks to enable broader participation, and established trojan detection and red teaming baselines will be provided as a starting point. By uniting trojan detection and red teaming, TDC 2023 aims to foster collaboration between these communities to promote research on hidden functionality in LLMs and enhance the robustness and security of AI systems.
Machine Learning for Physical and Life Sciences
Weather4cast 2023 – Data Fusion for Quantitative Hi-Res Rain Movie Prediction under Spatio-temporal Shifts
Aleksandra Gruca (Silesian University of Technology, Poland), Pilar Rípodas (Spanish Meteorological Agency ,AEMET, Spain), Xavier Calbet (Spanish Meteorological Agency ,AEMET, Spain), Llorenç Lliso (Spanish Meteorological Agency ,AEMET, Spain), Federico Serva (Institute of Marine Sciences, CNR-ISMAR, Italy), Bertrand Le Saux (European Space Agency, Italy), Michael Kopp, David Kreil, Sepp Hochreiter (Johannes Kepler University Linz, Austria)
Contact: neurips23@weather4cast.org
 The competition will advance modern algorithms in AI and machine learning through a highly topical interdisciplinary competition challenge: The prediction of hi-res rain radar movies from multi-band satellite sensors requires data fusion of complementary signal sources, multi-channel video frame prediction, as well as super-resolution techniques. To reward models that extract relevant mechanistic patterns reflecting the underlying complex weather systems our evaluation incorporates spatio-temporal shifts: Specifically, algorithms need to forecast 8h of ground-based hi-res precipitation radar from lo-res satellite spectral images in a unique cross-sensor prediction challenge. Models are evaluated within and across regions on Earth with diverse climate and different distributions of heavy precipitation events. Conversely, robustness over time is achieved by testing predictions on data one year after the training period.
The competition will advance modern algorithms in AI and machine learning through a highly topical interdisciplinary competition challenge: The prediction of hi-res rain radar movies from multi-band satellite sensors requires data fusion of complementary signal sources, multi-channel video frame prediction, as well as super-resolution techniques. To reward models that extract relevant mechanistic patterns reflecting the underlying complex weather systems our evaluation incorporates spatio-temporal shifts: Specifically, algorithms need to forecast 8h of ground-based hi-res precipitation radar from lo-res satellite spectral images in a unique cross-sensor prediction challenge. Models are evaluated within and across regions on Earth with diverse climate and different distributions of heavy precipitation events. Conversely, robustness over time is achieved by testing predictions on data one year after the training period.
Now, in its third edition, weather4cast 2023 moves to improve rain forecasts world-wide on an expansive data set and novel quantitative prediction challenges. Accurate rain predictions are becoming ever more critical for everyone, with climate change increasing the frequency of extreme precipitation events. Notably, the new models and insights will have a particular impact for the many regions on Earth where costly weather radar data are not available.
Foundation Model Prompting for Medical Image Classification Challenge 2023
Dequan Wang (Shanghai Jiao Tong University), Xiaosong Wang (Shanghai AI Lab), Qi Dou (Chinese University of Hong Kong), Xiaoxiao Li (University of British Columbia), Qian Da (Shanghai Ruijin Hospital), Jun Shen (Shanghai Renji Hospital), Feng Gao (Sixth Affiliated Hospital of Sun Yat-sen University), Fangfang Cui (First Affiliated Hospital of Zhengzhou University), Kang Li (West China Hospital), Dimitris Metaxas (Rutgers University), Shaoting Zhang (Shanghai AI Lab)
Contact: openmedlab@pjlab.org.cn
 The lack of public availability and quality annotations in medical image data has been the bottleneck for training large-scale deep learning models for many clinical downstream applications. It remains a tedious and time-consuming job for medical professionals to hand-label volumetric data repeatedly while providing a few differentiable sample cases is more logically feasible and complies with the training process of medical residents. The proposed challenge aims to advance technique in prompting large-scale pre-trained foundation models via a few data samples as a new paradigm for medical image analysis, e.g., classification tasks proposed here as use cases. It aligns with the recent trend and success of building foundation models (e.g., Vision Transformers, GPT-X, and CLIP) for a variety of downstream applications. Three private datasets for different classification tasks, i.e., thoracic disease classification, pathological tumor tissue classification, and colonoscopy lesion classification, are composed as the training (few samples) and validation sets (the rest of each dataset). Participants are encouraged to advance cross-domain knowledge transfer techniques in such a setting and achieve higher performance scores in all three tasks. The final evaluation will be conducted in the same tasks on the reserved private datasets.
The lack of public availability and quality annotations in medical image data has been the bottleneck for training large-scale deep learning models for many clinical downstream applications. It remains a tedious and time-consuming job for medical professionals to hand-label volumetric data repeatedly while providing a few differentiable sample cases is more logically feasible and complies with the training process of medical residents. The proposed challenge aims to advance technique in prompting large-scale pre-trained foundation models via a few data samples as a new paradigm for medical image analysis, e.g., classification tasks proposed here as use cases. It aligns with the recent trend and success of building foundation models (e.g., Vision Transformers, GPT-X, and CLIP) for a variety of downstream applications. Three private datasets for different classification tasks, i.e., thoracic disease classification, pathological tumor tissue classification, and colonoscopy lesion classification, are composed as the training (few samples) and validation sets (the rest of each dataset). Participants are encouraged to advance cross-domain knowledge transfer techniques in such a setting and achieve higher performance scores in all three tasks. The final evaluation will be conducted in the same tasks on the reserved private datasets.
The Dynamic Sensorium competition for predicting large-scale mouse visual cortex activity from videos
Polina Turishcheva (University of Göttingen), Paul G. Fahey (Baylor College of Medicine), Laura Hansel (University of Göttingen), Rachel Froebe (Baylor College of Medicine), Kayla Ponder (Baylor College of Medicine), Michaela Vystrčilová (University of Göttingen), Konstantin Willeke (University of Tübingen), Mohammad Bashiri(University of Tübingen), Eric Wang (Baylor College of Medicine), Zhiwei Ding (Baylor College of Medicine), Andreas S. Tolias (Baylor College of Medicine), Fabian Sinz (University of Göttingen), Alexander S. Ecker (University of Göttingen)
Contact: contact@sensorium-competition.net
 Understanding how biological visual systems process information is challenging due to the complex nonlinear relationship between neuronal responses and high- dimensional visual input. Artificial neural networks have already improved our understanding of this system by allowing computational neuroscientists to create predictive models and bridge biological and machine vision. During the Sensorium 2022 competition, we introduced benchmarks for vision models with static input (i.e. images). However, animals operate and excel in dynamic environments, making it crucial to study and understand how the brain functions under these conditions. Moreover, many biological theories, such as predictive coding, suggest that previous input is crucial for current input processing. Currently, there is no standardized benchmark to identify state-of-the-art dynamic models of the mouse visual system. To address this gap, we propose the Sensorium 2023 Benchmark Competition with dynamic input. This competition includes the collection of a new large-scale dataset from the primary visual cortex of five mice, containing responses from over 38,000 neurons to over 2 hours of dynamic stimuli per neuron. Participants in the main benchmark track will compete to identify the best predictive models of neuronal responses for dynamic input (i.e. video). We will also host a bonus track in which submission performance will be evaluated on out-of-domain input, using withheld neuronal responses to dynamic input stimuli whose statistics differ from the training set. Both tracks will offer behavioral data along with video stimuli. As before, we will provide code, tutorials, and strong pre-trained baseline models to encourage participation. We hope this competition will continue to strengthen the accompanying Sensorium benchmarks collection as a standard tool to measure progress in large-scale neural system identification models of the entire mouse visual hierarchy and beyond.
Understanding how biological visual systems process information is challenging due to the complex nonlinear relationship between neuronal responses and high- dimensional visual input. Artificial neural networks have already improved our understanding of this system by allowing computational neuroscientists to create predictive models and bridge biological and machine vision. During the Sensorium 2022 competition, we introduced benchmarks for vision models with static input (i.e. images). However, animals operate and excel in dynamic environments, making it crucial to study and understand how the brain functions under these conditions. Moreover, many biological theories, such as predictive coding, suggest that previous input is crucial for current input processing. Currently, there is no standardized benchmark to identify state-of-the-art dynamic models of the mouse visual system. To address this gap, we propose the Sensorium 2023 Benchmark Competition with dynamic input. This competition includes the collection of a new large-scale dataset from the primary visual cortex of five mice, containing responses from over 38,000 neurons to over 2 hours of dynamic stimuli per neuron. Participants in the main benchmark track will compete to identify the best predictive models of neuronal responses for dynamic input (i.e. video). We will also host a bonus track in which submission performance will be evaluated on out-of-domain input, using withheld neuronal responses to dynamic input stimuli whose statistics differ from the training set. Both tracks will offer behavioral data along with video stimuli. As before, we will provide code, tutorials, and strong pre-trained baseline models to encourage participation. We hope this competition will continue to strengthen the accompanying Sensorium benchmarks collection as a standard tool to measure progress in large-scale neural system identification models of the entire mouse visual hierarchy and beyond.
Single-cell perturbation prediction: generalizing experimental interventions to unseen contexts
Daniel Burkhardt (Cellarity), Andrew Benz (Cellarity), Robrecht Cannoodt (Data Intuitive), Mauricio Cortes (Cellarity), Scott Gigante (Immunai), Christopher Lance (Helmholtz Muenchen), Richard Lieberman (Cellarity), Malte Luecken (Helmholtz Muenchen), Angela Pisco (insitro)
Contact: neurips@cellarity.com
 Single-cell sequencing technologies have revolutionized our understanding of the heterogeneity and dynamics of cells and tissues. However, single-cell data analysis faces challenges such as high dimensionality, sparsity, noise, and limited ground truth. In this 3rd installment in the Open Problems in Single-Cell Analysis competitions at NeurIPS, we challenge competitors to develop algorithms capable of predicting single-cell perturbation response across experimental conditions and cell types. We will provide a new benchmark dataset of human peripheral blood cells under chemical perturbations, which simulate drug discovery experiments. The objective is to develop methods that can generalize to unseen perturbations and cell types to enable scientists to overcome the practical and economic limitations of single-cell perturbation studies. The goal of this competition is to leverage advances in representation learning (in particular, self-supervised, multi-view, and transfer learning) to unlock new capabilities bridging data science, machine learning, and computational biology. We hope this effort will continue to foster collaboration between the computational biology and machine learning communities to advance the development of algorithms for biomedical data.
Single-cell sequencing technologies have revolutionized our understanding of the heterogeneity and dynamics of cells and tissues. However, single-cell data analysis faces challenges such as high dimensionality, sparsity, noise, and limited ground truth. In this 3rd installment in the Open Problems in Single-Cell Analysis competitions at NeurIPS, we challenge competitors to develop algorithms capable of predicting single-cell perturbation response across experimental conditions and cell types. We will provide a new benchmark dataset of human peripheral blood cells under chemical perturbations, which simulate drug discovery experiments. The objective is to develop methods that can generalize to unseen perturbations and cell types to enable scientists to overcome the practical and economic limitations of single-cell perturbation studies. The goal of this competition is to leverage advances in representation learning (in particular, self-supervised, multi-view, and transfer learning) to unlock new capabilities bridging data science, machine learning, and computational biology. We hope this effort will continue to foster collaboration between the computational biology and machine learning communities to advance the development of algorithms for biomedical data.
Open Catalyst Challenge
Brandon M. Wood (FAIR, Meta AI), Muhammed Shuaibi (FAIR, Meta AI), Brook Wander (Carnegie Mellon University), Jehad Abed (FAIR, Meta AI), Abhishek Das (FAIR, Meta AI), Siddharth Goyal (FAIR, Meta AI), John R. Kitchin (Carnegie Mellon University), Adeesh Kolluru (Carnegie Mellon University), Janice Lan (FAIR, Meta AI), Joseph Musielewicz (Carnegie Mellon University), Ammar Rizvi (FAIR, Meta AI), Nima Shoghi (FAIR, Meta AI), Anuroop Sriram (FAIR, Meta AI), Zachary Ulissi (FAIR, Meta AI), Matt Uyttendaele (FAIR, Meta AI), C. Lawrence Zitnick (FAIR, Meta AI)
Contact: opencatalystproject@gmail.com
 The Open Catalyst Challenge is aimed at encouraging the community to make progress on this consequential problem of catalyst materials discovery. An important proxy for catalyst performance is the adsorption energy, i.e. how strongly the adsorbate molecule binds to the catalyst’s surface. This year’s challenge will consist of one primary task – find the adsorption energy (global minimum) given an adsorbate and a catalyst surface. Adsorption energies can be used for screening catalysts and as a result this task will directly support the acceleration of computational discovery of novel catalysts for sustainable energy applications.
The Open Catalyst Challenge is aimed at encouraging the community to make progress on this consequential problem of catalyst materials discovery. An important proxy for catalyst performance is the adsorption energy, i.e. how strongly the adsorbate molecule binds to the catalyst’s surface. This year’s challenge will consist of one primary task – find the adsorption energy (global minimum) given an adsorbate and a catalyst surface. Adsorption energies can be used for screening catalysts and as a result this task will directly support the acceleration of computational discovery of novel catalysts for sustainable energy applications.
Multi-Agent Learning
The NeurIPS 2023 Neural MMO Challenge: Multi-Task Reinforcement Learning and Curriculum Generation
Joseph Suarez (Massachusetts Institute of Technology)*; Phillip Isola (MIT); David Bloomin (CarperAI); Kyoung Choe (CarperAI); Hao Li (CarperAI); Ryan Sullivan (University of Maryland); Nishaanth Kanna (CarperAI); Daniel Scott (CarperAI); Rose Shuman (CarperAI); Herbie Bradley (University of Cambridge); Louis J Castricato (Georgia Tech); Kirsty You (Parametrix.ai); Yuhao Jiang (Parametrix.AI); Qimai Li (Parametrix.AI); jiaxin chen (parametrix.ai); Xiaolong Zhu (CarperAI); Dipam Chakraborty (AIcrowd); Sharada Mohanty (AICrowd)
Contact: jsuarez@mit.edu
 In this competition, we challenge participants to create teams of 8 agents to complete a variety of tasks involving foraging, combat, tool acquisition and usage, and item trading in Neural MMO 2.0, a simulated environment featuring 128 players and procedurally generated maps. The competition includes two tracks focused on multi-agent reinforcement learning and curriculum generation, respectively. This is the fourth challenge on Neural MMO, and the previous competitions have all yielded state-of-the-art performance on earlier versions of this environment as well as more general improvements to learning methods. We will provide the full source code of the environment, an easy to use starter kit, baselines for both tracks, and 200,000 A100 hours of GPU time for training and evaluating participants' submissions. Success in this competition would produce robust, task-conditional learning methods and establish a new benchmark for the same.
In this competition, we challenge participants to create teams of 8 agents to complete a variety of tasks involving foraging, combat, tool acquisition and usage, and item trading in Neural MMO 2.0, a simulated environment featuring 128 players and procedurally generated maps. The competition includes two tracks focused on multi-agent reinforcement learning and curriculum generation, respectively. This is the fourth challenge on Neural MMO, and the previous competitions have all yielded state-of-the-art performance on earlier versions of this environment as well as more general improvements to learning methods. We will provide the full source code of the environment, an easy to use starter kit, baselines for both tracks, and 200,000 A100 hours of GPU time for training and evaluating participants' submissions. Success in this competition would produce robust, task-conditional learning methods and establish a new benchmark for the same.
Lux AI Challenge Season 2 NeurIPS Edition
Stone Tao (UC San Diego), Qimai Li (Parametrix.AI), Yuhao Jiang (Parametrix.AI), Jiaxin Chen (Parametrix.AI), Xiaolong Zhu (Parametrix.AI), Bovard Doerschuk-Tiberi (Kaggle), Isabelle Pan (UC San Diego), Addison Howard (Kaggle)
Contact: organizers@lux-ai.org
 The proposed challenge is a large-scale multi-agent environment with novel complex dynamics, featuring long-horizon planning, perfect information, and more. The challenge uniquely presents an opportunity to investigate problems at a large-scale in two forms, large-scale RL training via GPU optimized environments powered by Jax, as well as large populations of controllable units in the environments. The Lux AI Challenge Season 2 NeurIPS Edition presents a benchmark to test the scaling capabilities of solutions such as RL on environement settings of increasing scale and complexity. Participants can easily get started using any number of strong rule-based, RL, and/or imitation learning (IL) baselines. They are also given access to more than a billion frames of "play" data from the previous iteration of the competition on the small scale version of the environment previously hosted on Kaggle. Participants can submit their agents to compete against other submitted agents on a online leaderboard ranked by a Trueskill ranking system.
The proposed challenge is a large-scale multi-agent environment with novel complex dynamics, featuring long-horizon planning, perfect information, and more. The challenge uniquely presents an opportunity to investigate problems at a large-scale in two forms, large-scale RL training via GPU optimized environments powered by Jax, as well as large populations of controllable units in the environments. The Lux AI Challenge Season 2 NeurIPS Edition presents a benchmark to test the scaling capabilities of solutions such as RL on environement settings of increasing scale and complexity. Participants can easily get started using any number of strong rule-based, RL, and/or imitation learning (IL) baselines. They are also given access to more than a billion frames of "play" data from the previous iteration of the competition on the small scale version of the environment previously hosted on Kaggle. Participants can submit their agents to compete against other submitted agents on a online leaderboard ranked by a Trueskill ranking system.
Melting Pot Contest
Rakshit S. Trivedi (Massachusetts Institute of Technology), Akbir Khan (University College London, Cooperative AI Foundation), Jesse Clifton (Center on Long-Term Risk, North Carolina State University, Cooperative AI Foundation), Lewis Hammond (University of Oxford, Cooperative AI Foundation), John P. Agapiou (Google DeepMind), Edgar A. Dueñez-Guzman (Google DeepMind), Jayd Matyas (Google DeepMind), Dylan Hadfield-Menell (Massachusetts Institute of Technology), Joel Z. Leibo (Google DeepMind)
Contact: Site Forums
 Multi-agent AI research promises a path to develop human-like and human-compatible intelligent technologies that complement the solipsistic view of other approaches, which mostly do not consider interactions between agents. We propose a Cooperative AI contest based on the Melting Pot framework. At its core, Melting Pot provides an evaluation protocol that measures generalization to novel social partners in a set of canonical test scenarios. There exist several benchmarks, challenges, and contests aimed at spurring research on cooperation in multi-agent learning. Melting Pot expands and generalizes these previous efforts in several ways: (1) it focuses on mixed-motive games, (as opposed to purely cooperative or competitive games); (2) it enables testing generalizability of agent cooperation to previously unseen coplayers; (3) it consists of a suite of multiple environments rather than a single one; and (4) it includes games with larger numbers of players (> 7). These properties make it an accessible while also challenging framework for multi-agent AI research. For this contest, we invite multi-agent reinforcement learning solutions that focus on driving cooperation between interacting agents in the Melting Pot environments and generalize to new situations beyond training. A scoring mechanism based on metrics representative of cooperative intelligence will be used to measure success of the solutions. We believe that Melting Pot can serve as a clear benchmark to drive progress on Cooperative AI, as it focuses specifically on evaluating social intelligence of both groups and individuals. As an overarching goal, we are excited in assessing the implications of current definitions of cooperative intelligence on resulting solution approaches and studying the emerging behaviors of proposed solutions to inform future research directions in Cooperative AI.
Multi-agent AI research promises a path to develop human-like and human-compatible intelligent technologies that complement the solipsistic view of other approaches, which mostly do not consider interactions between agents. We propose a Cooperative AI contest based on the Melting Pot framework. At its core, Melting Pot provides an evaluation protocol that measures generalization to novel social partners in a set of canonical test scenarios. There exist several benchmarks, challenges, and contests aimed at spurring research on cooperation in multi-agent learning. Melting Pot expands and generalizes these previous efforts in several ways: (1) it focuses on mixed-motive games, (as opposed to purely cooperative or competitive games); (2) it enables testing generalizability of agent cooperation to previously unseen coplayers; (3) it consists of a suite of multiple environments rather than a single one; and (4) it includes games with larger numbers of players (> 7). These properties make it an accessible while also challenging framework for multi-agent AI research. For this contest, we invite multi-agent reinforcement learning solutions that focus on driving cooperation between interacting agents in the Melting Pot environments and generalize to new situations beyond training. A scoring mechanism based on metrics representative of cooperative intelligence will be used to measure success of the solutions. We believe that Melting Pot can serve as a clear benchmark to drive progress on Cooperative AI, as it focuses specifically on evaluating social intelligence of both groups and individuals. As an overarching goal, we are excited in assessing the implications of current definitions of cooperative intelligence on resulting solution approaches and studying the emerging behaviors of proposed solutions to inform future research directions in Cooperative AI.
Urban and Environmental Challenges
The CityLearn Challenge 2023
Zoltan Nagy (The University of Texas at Austin), Kingsley Nweye (The University of Texas at Austin), Sharada Mohanty (AI Crowd), Ruchi Choudhary (University of Cambridge), Max Langtry (University of Cambridge), Gregor Henze (University of Colorado), Jan Drgona (Pacific Northwest National Laboratory), Sourav Dey (University of Colorado), Alfonso Capozzoli (Politecnico di Torino), Mohamed Ouf (Concordia University)
Contact: nagy@utexas.edu
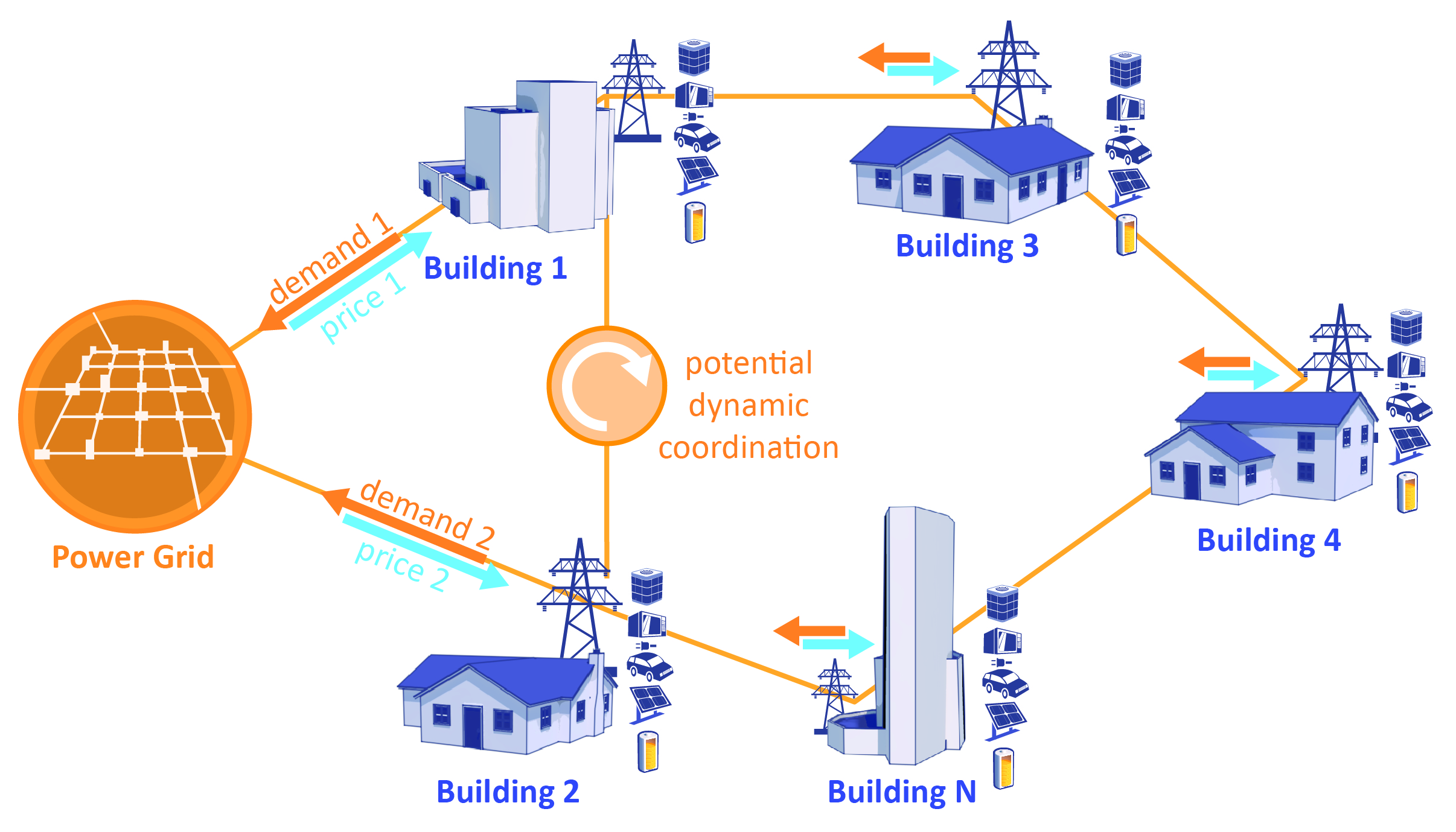 Reinforcement learning has gained popularity as a model-free and adaptive controller for the built-environment in demand-response applications. However, a lack of standardization on previous research has made it difficult to compare different RL algorithms with each other. Also, it is unclear how much effort is required in solving each specific problem in the building domain and how well a trained RL agent will scale up to new environments. The CityLearn Challenge 2023 provides an avenue to address these problems by leveraging CityLearn, an OpenAI Gym Environment for the implementation of RL agents for demand response. The challenge utilizes a novel dataset based on the US end use load profile database. Participants are to develop energy management agents for battery charge and discharge control in each building with a goal of minimizing electricity demand from the grid, electricity bill and greenhouse gas emissions. We provide a baseline RBC agent for the evaluation of the RL agents performance and rank the participants' according to their solution's ability to outperform the baseline.
Reinforcement learning has gained popularity as a model-free and adaptive controller for the built-environment in demand-response applications. However, a lack of standardization on previous research has made it difficult to compare different RL algorithms with each other. Also, it is unclear how much effort is required in solving each specific problem in the building domain and how well a trained RL agent will scale up to new environments. The CityLearn Challenge 2023 provides an avenue to address these problems by leveraging CityLearn, an OpenAI Gym Environment for the implementation of RL agents for demand response. The challenge utilizes a novel dataset based on the US end use load profile database. Participants are to develop energy management agents for battery charge and discharge control in each building with a goal of minimizing electricity demand from the grid, electricity bill and greenhouse gas emissions. We provide a baseline RBC agent for the evaluation of the RL agents performance and rank the participants' according to their solution's ability to outperform the baseline.
Autonomous Systems and Task Execution
The HomeRobot Open Vocabulary Mobile Manipulation Challenge
Sriram Yenamandra (Georgia Tech), Arun Ramachandran (Georgia Tech), Mukul Khanna (Georgia Tech), Karmesh Yadav (FAIR, Meta AI), Devendra Singh Chaplot (FAIR, Meta AI), Gunjan Chhablani (Georgia Tech), Alexander Clegg (FAIR, Meta AI), Theophile Gervet (Carnegie Mellon and FAIR, Meta AI), Vidhi Jain (Carnegie Mellon), Ruslan Partsey (FAIR, Meta AI), Ram Ramrakhya (Georgia Tech), Andrew Szot (Georgia Tech), Austin Wang (FAIR, Meta AI), Tsung-Yen Yang (FAIR, Meta AI), Aaron Edsinger (Hello Robot) & Charlie Kemp (Georgia Tech and Hello Robot), Binit Shah (Hello Robot), Zsolt Kira (Georgia Tech), Dhruv Batra (FAIR, Meta AI and Georgia Tech) & Roozbeh Mottaghi (FAIR, Meta AI), Yonatan Bisk (Carnegie Mellon and FAIR, Meta AI), Chris Paxton (FAIR, Meta AI)
Contact: homerobot-info@googlegroups.com
 Deploying robots in real human environments requires a full hardware and software stack, that includes everything from perception to manipulation, in simulation and on accessible physical hardware. The lack of a single unified resource providing these capabilities means that the academic literature often focuses on creating agents in simulation or on one-off hardware, preventing comprehensive benchmarking and reproducibility. We present the first Open-Vocabulary Mobile Manipulation challenge with diverse assets and environments in simulation and a different, held-out set of physical objects in a novel real-world environment. We provide an entire robotics software stack that is modular, fully open-source, and centered on a popular low-cost hardware platform for easy replication and extension by the research community. Machine learning has benefited greatly from the standardization of high-quality engineering; our work aims to lower the cost of entry to robotics.
Deploying robots in real human environments requires a full hardware and software stack, that includes everything from perception to manipulation, in simulation and on accessible physical hardware. The lack of a single unified resource providing these capabilities means that the academic literature often focuses on creating agents in simulation or on one-off hardware, preventing comprehensive benchmarking and reproducibility. We present the first Open-Vocabulary Mobile Manipulation challenge with diverse assets and environments in simulation and a different, held-out set of physical objects in a novel real-world environment. We provide an entire robotics software stack that is modular, fully open-source, and centered on a popular low-cost hardware platform for easy replication and extension by the research community. Machine learning has benefited greatly from the standardization of high-quality engineering; our work aims to lower the cost of entry to robotics.
We have assembled a team that spans Georgia Tech, Carnegie Mellon, Meta and Hello Robot to enable physical robot evaluations at NeurIPS. A simulator is ready for deployment and physical kitchens have been constructed for use as a real-world test set. We present development environments here and a peek at the construction of our full held-out test apartment being constructed in Fremont, California. Crucially, we are releasing a full software control stack for the Hello Robot Stretch, and have university partners to beta-test.
ROAD-R 2023: the Road Event Detection with Requirements Challenge
Eleonora Giunchiglia (TU Wien), Mihaela Cătălina Stoian (University of Oxford), Salman Khan (Oxford Brookes University), Reza Javanmard Alitappeh (Mazandaran University of Science and Technology), Izzeddin Teeti (Oxford Brookes University), Adrian Paschke (Freie Universität Berlin), Fabio Cuzzolin (Oxford Brookes University), Thomas Lukasiewicz (TU Wien, University of Oxford)
Contact: roadr-organizers@googlegroups.com
 In recent years, there has been an increasing interest in exploiting readily available background knowledge in order to obtain neural models (i) able to learn from less data, and/or (ii) guaranteed to be compliant with the background knowledge corresponding to requirements about the model. In this challenge, we focus on the autonomous driving domain, and we provide our participants with the recently proposed ROAD-R dataset, which consists of 22 long videos annotated with road events together with a set of requirements expressing well known facts about the world (e.g., “a traffic light cannot be red and green at the same time”). The participants will face two challenging tasks. In the first, they will have to develop the best performing model with only a subset of the annotated data, which in turn will encourage them to exploit the requirements to facilitate training on the unlabelled portion of the dataset. In the second, we ask them to create systems whose predictions are compliant with the requirements. This is the first competition addressing the open questions: (i) If limited annotated data is available, is background knowledge useful to obtain good performance? If so, how can it be injected in deep learning models? And, (ii) how can we design effective deep learning based systems that are compliant with a set of requirements? As a consequence, this challenge is expected to bring together people from different communities, especially those interested in the general topic of Safe-AI as well as in the autonomous driving application domain, and also researchers working in the neuro-symbolic AI, semi-supervised learning and action recognition.
In recent years, there has been an increasing interest in exploiting readily available background knowledge in order to obtain neural models (i) able to learn from less data, and/or (ii) guaranteed to be compliant with the background knowledge corresponding to requirements about the model. In this challenge, we focus on the autonomous driving domain, and we provide our participants with the recently proposed ROAD-R dataset, which consists of 22 long videos annotated with road events together with a set of requirements expressing well known facts about the world (e.g., “a traffic light cannot be red and green at the same time”). The participants will face two challenging tasks. In the first, they will have to develop the best performing model with only a subset of the annotated data, which in turn will encourage them to exploit the requirements to facilitate training on the unlabelled portion of the dataset. In the second, we ask them to create systems whose predictions are compliant with the requirements. This is the first competition addressing the open questions: (i) If limited annotated data is available, is background knowledge useful to obtain good performance? If so, how can it be injected in deep learning models? And, (ii) how can we design effective deep learning based systems that are compliant with a set of requirements? As a consequence, this challenge is expected to bring together people from different communities, especially those interested in the general topic of Safe-AI as well as in the autonomous driving application domain, and also researchers working in the neuro-symbolic AI, semi-supervised learning and action recognition.
The Robot Air Hockey Challenge: Robust, Reliable, and Safe Learning Techniques for Real-world Robotics
Puze Liu (Technical University Darmstadt), Jonas Günster (Technical University Darmstadt), Niklas Funk (Technical University Darmstadt), Dong Chen (Huawei), Ziyuan Liu (Huawei), Haitham Bou-Ammar (Huawei), Davide Tateo (Technical University Darmstadt), Jan Peters (Technical University Darmstadt)
Contact: air-hockey-challenge@robot-learning.net
 While machine learning methods demonstrated impressive success in many application domains, their impact on real robotic platforms is still far from their potential. To unleash the capabilities of machine learning in the field of robotics, researchers need to cope with specific challenges and issues of the real world. While many robotics benchmarks are available for machine learning, most simplify the complexity of classical robotics tasks, for example neglecting highly nonlinear dynamics of the actuators, such as stiction. We organize the robot air hockey challenge, which allows machine learning researchers to face the sim-to-real-gap in a complex and dynamic environment while competing with each other. In particular, the challenge focuses on robust, reliable, and safe learning techniques suitable for real-world robotics. Through this challenge, we wish to investigate how machine learning techniques can outperform standard robotics approaches in challenging robotic scenarios while dealing with safety, limited data usage, and real-time requirements.
While machine learning methods demonstrated impressive success in many application domains, their impact on real robotic platforms is still far from their potential. To unleash the capabilities of machine learning in the field of robotics, researchers need to cope with specific challenges and issues of the real world. While many robotics benchmarks are available for machine learning, most simplify the complexity of classical robotics tasks, for example neglecting highly nonlinear dynamics of the actuators, such as stiction. We organize the robot air hockey challenge, which allows machine learning researchers to face the sim-to-real-gap in a complex and dynamic environment while competing with each other. In particular, the challenge focuses on robust, reliable, and safe learning techniques suitable for real-world robotics. Through this challenge, we wish to investigate how machine learning techniques can outperform standard robotics approaches in challenging robotic scenarios while dealing with safety, limited data usage, and real-time requirements.
MyoChallenge 2023: Towards Human-Level Dexterity and Agility
Vittorio Caggiano (Meta AI), Huawei Wang (University of Twente), Guillaume Durandau (McGill University), Seungmoon Song (Northeastern University), Chun Kwang Tan (Northeastern University), Cameron Berg (Meta AI), Pierre Schumacher (Max Planck Institute for Intelligent Systems and Hertie Institute for Clinical Brain Research), Massimo Sartori (University of Twente), Vikash Kumar (Meta AI)
Contact: myosuite@gmail.com
 Humans effortlessly grasp objects of diverse shapes and properties and execute agile locomotion without overwhelming their cognitive capacities. This ability was acquired through millions of years of evolution, which honed the symbiotic relationship between the central and peripheral nervous systems and the musculoskeletal structure. Consequently, it is not surprising that uncovering the intricacies of these complex, evolved systems underlying human movement remains a formidable challenge. Advancements in neuromechanical simulations and data driven methods offer promising avenues to overcome these obstacles. To this end, we propose to organize \longName, where we will provide a highly detailed neuromechanical simulation environment and invite experts to develop any type of controller, including state-of-the-art reinforcement learning. Building on the success of NeurIPS 2022: MyoChallenge, which focused on manipulating single objects with a highly articulated musculoskeletal hand, this year's competition will feature two tracks: the manipulation track and the locomotion track. The manipulation track will utilize a substantially extended musculoskeletal model of the hand with added elbow and shoulder, MyoArm, which has 27 DOFs controlled by 63 muscles, and aims to realize generalizable manipulation for unseen objects. The new locomotion track will feature the newly developed MyoLeg, which represents the full body with articulated legs featuring 16 DOFs controlled by 80 muscles. This track aims to push the boundaries of agile locomotion and benchmark the World Chase Tag match. The competition is not only suitable for testing state-of-the-art reinforcement learning techniques but will also advance our understanding of human movement toward improved rehabilitation and assistive technologies.
Humans effortlessly grasp objects of diverse shapes and properties and execute agile locomotion without overwhelming their cognitive capacities. This ability was acquired through millions of years of evolution, which honed the symbiotic relationship between the central and peripheral nervous systems and the musculoskeletal structure. Consequently, it is not surprising that uncovering the intricacies of these complex, evolved systems underlying human movement remains a formidable challenge. Advancements in neuromechanical simulations and data driven methods offer promising avenues to overcome these obstacles. To this end, we propose to organize \longName, where we will provide a highly detailed neuromechanical simulation environment and invite experts to develop any type of controller, including state-of-the-art reinforcement learning. Building on the success of NeurIPS 2022: MyoChallenge, which focused on manipulating single objects with a highly articulated musculoskeletal hand, this year's competition will feature two tracks: the manipulation track and the locomotion track. The manipulation track will utilize a substantially extended musculoskeletal model of the hand with added elbow and shoulder, MyoArm, which has 27 DOFs controlled by 63 muscles, and aims to realize generalizable manipulation for unseen objects. The new locomotion track will feature the newly developed MyoLeg, which represents the full body with articulated legs featuring 16 DOFs controlled by 80 muscles. This track aims to push the boundaries of agile locomotion and benchmark the World Chase Tag match. The competition is not only suitable for testing state-of-the-art reinforcement learning techniques but will also advance our understanding of human movement toward improved rehabilitation and assistive technologies.
Train Offline, Test Online: A Democratized Robotics Benchmark
Victoria Dean (CMU / Olin), Gaoyue Zhou (CMU / NYU), Mohan Kumar Srirama (CMU), Sudeep Dasari (CMU), Esther Brown (Harvard), Marion Lepert (Stanford), Jackie Kay (Google DeepMind), Paul Ruvolo (Olin), Chelsea Finn (Stanford), Lerrel Pinto (NYU), Abhinav Gupta (CMU)
Contact: info@toto-benchmark.org
 The Train Offline, Test Online (TOTO) competition provides a shared, remote robot setup paired with an open-source dataset. Participants can train offline agents (e.g. via behavior cloning or offline reinforcement learning) and evaluate them on two common manipulation tasks (pouring and scooping), which require challenging generalization across objects, locations, and lighting conditions. TOTO has an additional track for evaluating vision representations, which are combined with a standard behavior cloning method for evaluation. The competition begins with a simulation phase to qualify for the real-robot phase. We hope that TOTO will recruit newcomers to robotics by giving them a chance to compete and win on real hardware and the resources needed to get started.
The Train Offline, Test Online (TOTO) competition provides a shared, remote robot setup paired with an open-source dataset. Participants can train offline agents (e.g. via behavior cloning or offline reinforcement learning) and evaluate them on two common manipulation tasks (pouring and scooping), which require challenging generalization across objects, locations, and lighting conditions. TOTO has an additional track for evaluating vision representations, which are combined with a standard behavior cloning method for evaluation. The competition begins with a simulation phase to qualify for the real-robot phase. We hope that TOTO will recruit newcomers to robotics by giving them a chance to compete and win on real hardware and the resources needed to get started.
Program committee
We are very grateful to the colleagues that helped us review and select the competition proposals for this year
Alara Dirik (Bogazici University)
Aleksandr Panov (AIRI)
Aleksandra Gruca (Silesian University of Technology)
Annika Reinke (DKFZ)
Aravind Mohan (Waymo)
Bjoern Schuller (Imperial College London)
Byron Galbraith (Talla)
Cecile Germain (Université Paris Sud)
Chris Cameron (UBC)
Christian Eichenberger (IARAI)
Daniel Burkhardt (Cellarity)
David Kreil (Institute of Advanced Research in Artificial Intelligence (IARAI) GmbH)
David Rousseau (IJCLab-Orsay)
Dina Bashkirova (Boston University)
Dominik Baumann (Aalto University)
Dustin Carrion (TU Darmstadt)
Emilio Cartoni (Institute of Cognitive Sciences and Technologies )
Erhan Bilal (IBM Research)
Evelyne Viegas (Microsoft Research)
Geoffrey Siwo
George Tzanetakis (University of Victoria)
Gregory Clark (Google)
Haozhe Sun (Paris-Saclay University)
Heather Gray (Lawrence Berkeley National Lab)
Hsueh-Cheng (Nick) Wang (National Chiao Tung University)
Hugo Jair Escalante (INAOE)
Iuliia Kotseruba (York University)
Jean-roch Vlimant (California Institute of Technology)
Julio Saez-Rodriguez (Heidelberg University)
JUN MA (University of Toronto)
Karolis Ramanauskas (N/A)
Liantao Ma (Peking University)
Louis-Guillaume Gagnon (University of California)
Mantas Mazeika (UIUC)
Mikhail Burtsev (MIPT)
Moritz Neun (IARAI)
Odd Erik Gundersen (Norwegian University of Science and Technology)
Parth Patwa (PathCheck Foundation)
Pranay Manocha (Princeton University)
Rindra Ramamonjison (Huawei Technologies Canada)
Ron Bekkerman (Cherre)
Ryan Holbrook (Kaggle)
Sahika Genc (Amazon Artificial Intelligence)
Sanae Lotfi (New York University)
Tabitha Lee (Carnegie Mellon University)
Tao Lin (Westlake University)
Tianjian Zhang (The Chinese University of Hong Kong)
Walter Reade (Kaggle)
Xiaoxi Wei (Imperial College London)
Yetkin Yilmaz (LAL)
Yingshan CHANG (Carnegie Mellon University)
Yingzhen Li (Imperial College London)
Yonatan Bisk (Carnegie Mellon University)
Zhen Xu (4Paradigm)
Zoltan Nagy (The University of Texas at Austin)