Generalized Information-theoretic Multi-view Clustering
{kind=link}
Abstract
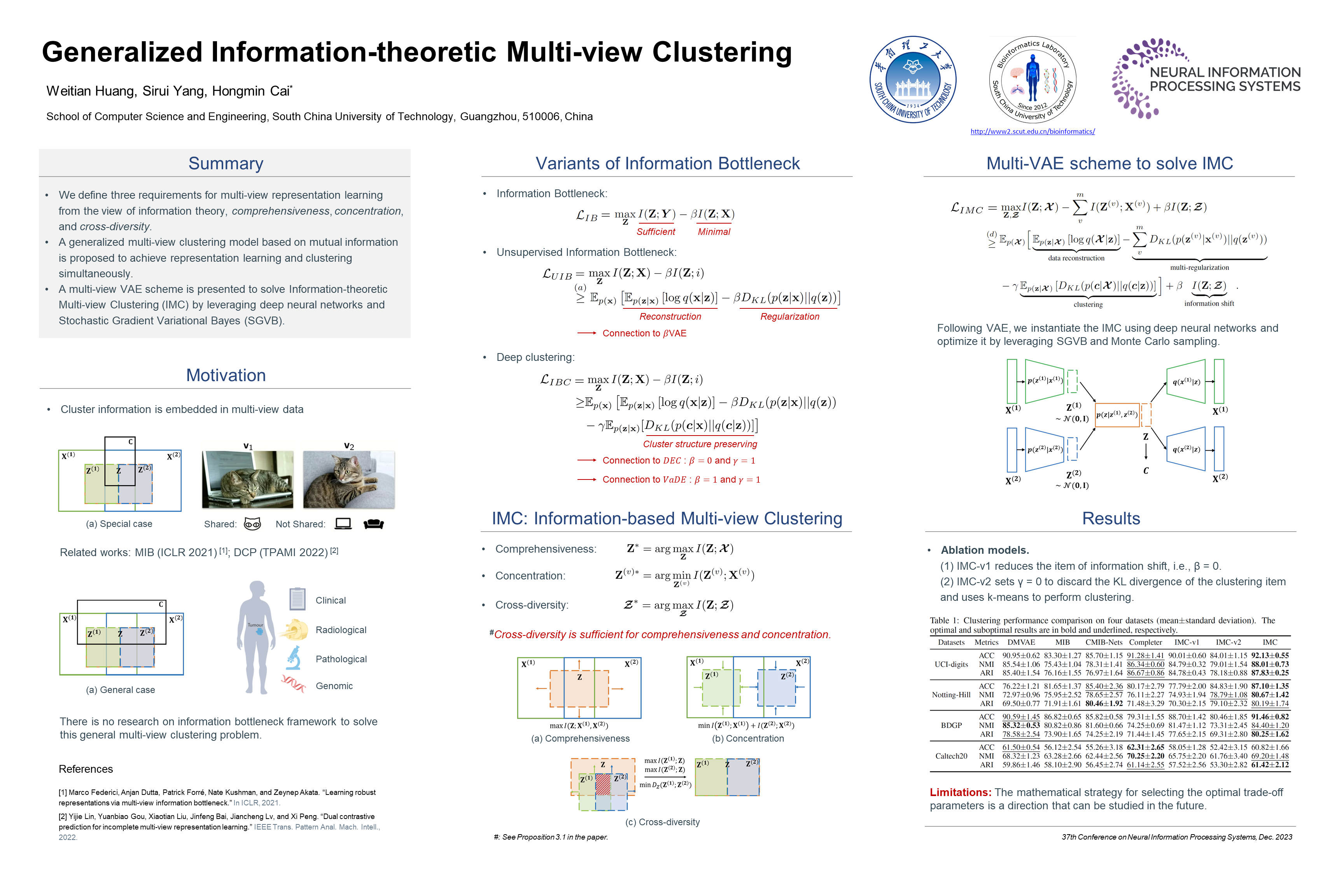
In an era of more diverse data modalities, multi-view clustering has become a fundamental tool for comprehensive data analysis and exploration. However, existing multi-view unsupervised learning methods often rely on strict assumptions on semantic consistency among samples. In this paper, we reformulate the multi-view clustering problem from an information-theoretic perspective and propose a general theoretical model. In particular, we define three desiderata under multi-view unsupervised learning in terms of mutual information, namely, comprehensiveness, concentration, and cross-diversity. The multi-view variational lower bound is then obtained by approximating the samples' high-dimensional mutual information. The Kullback–Leibler divergence is utilized to deduce sample assignments. Ultimately the information-based multi-view clustering model leverages deep neural networks and Stochastic Gradient Variational Bayes to achieve representation learning and clustering simultaneously. Extensive experiments on both synthetic and real datasets with wide types demonstrate that the proposed method exhibits a more stable and superior clustering performance than state-of-the-art algorithms.