Train Hard, Fight Easy: Robust Meta Reinforcement Learning
{kind=link}
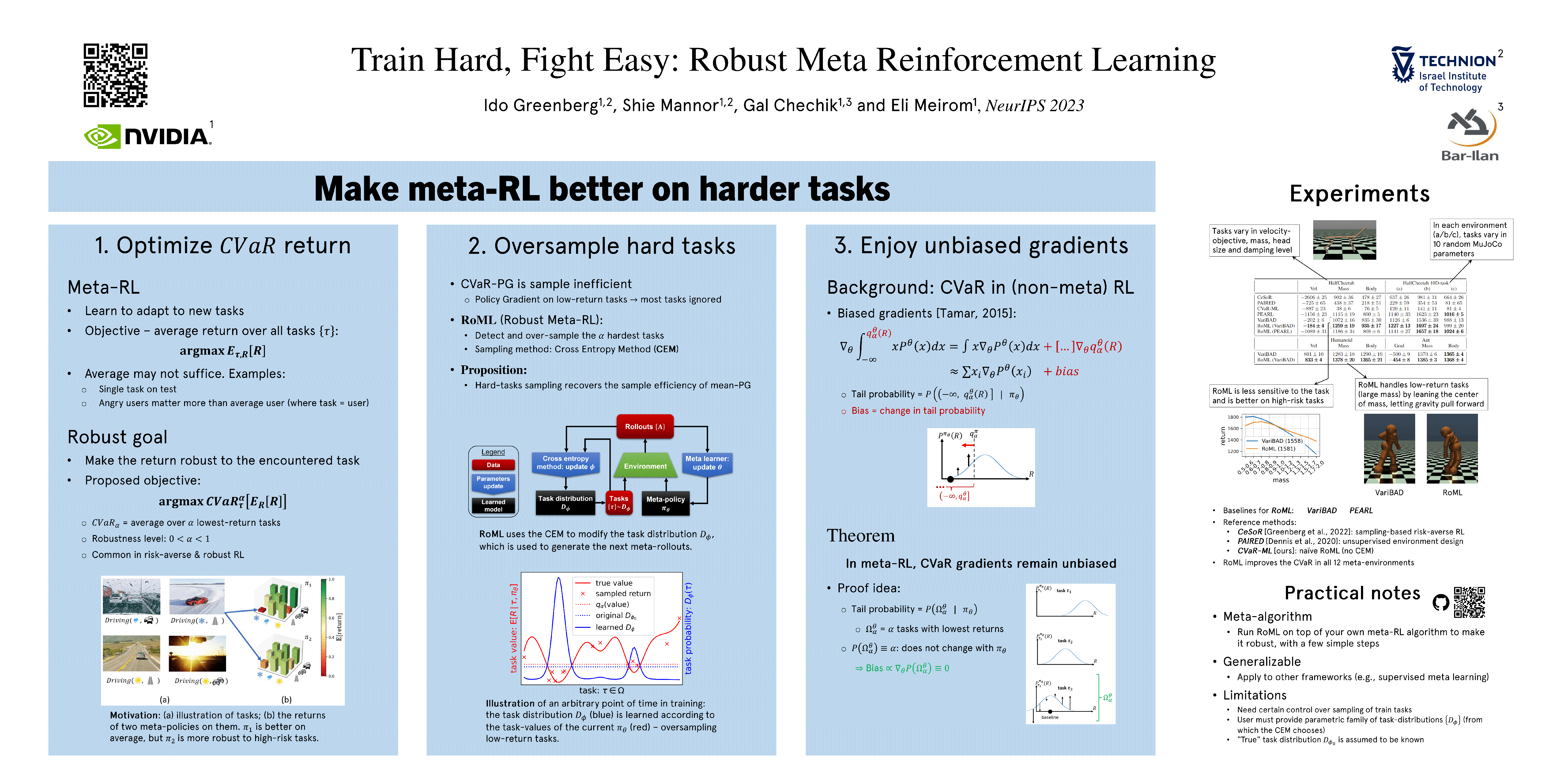
Abstract
A major challenge of reinforcement learning (RL) in real-world applications is the variation between environments, tasks or clients. Meta-RL (MRL) addresses this issue by learning a meta-policy that adapts to new tasks. Standard MRL methods optimize the average return over tasks, but often suffer from poor results in tasks of high risk or difficulty. This limits system reliability since test tasks are not known in advance. In this work, we define a robust MRL objective with a controlled robustness level. Optimization of analogous robust objectives in RL is known to lead to both biased gradients and data inefficiency. We prove that the gradient bias disappears in our proposed MRL framework. The data inefficiency is addressed via the novel Robust Meta RL algorithm (RoML). RoML is a meta-algorithm that generates a robust version of any given MRL algorithm, by identifying and over-sampling harder tasks throughout training. We demonstrate that RoML achieves robust returns on multiple navigation and continuous control benchmarks.