|
Best Paper Runner-up
|
Oral
[ West Exhibition Hall C, B3 ] Abstract
The primary axes of interest in image-generating diffusion models are image quality, the amount of variation in the results, and how well the results align with a given condition, e.g., a class label or a text prompt. The popular classifier-free guidance approach uses an unconditional model to guide a conditional model, leading to simultaneously better prompt alignment and higher-quality images at the cost of reduced variation. These effects seem inherently entangled, and thus hard to control. We make the surprising observation that it is possible to obtain disentangled control over image quality without compromising the amount of variation by guiding generation using a smaller, less-trained version of the model itself rather than an unconditional model. This leads to significant improvements in ImageNet generation, setting record FIDs of 1.01 for 64x64 and 1.25 for 512x512, using publicly available networks. Furthermore, the method is also applicable to unconditional diffusion models, drastically improving their quality.
|
|
Best Paper
|
Oral
[ East Meeting Room 1-3 ] 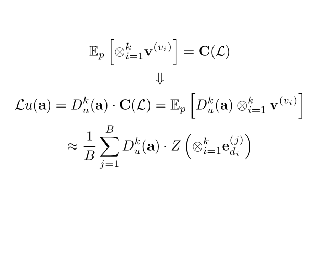
Abstract
Optimizing neural networks with loss that contain high-dimensional and high-order differential operators is expensive to evaluate with back-propagation due to $\mathcal{O}(d^{k})$ scaling of the derivative tensor size and the $\mathcal{O}(2^{k-1}L)$ scaling in the computation graph, where $d$ is the dimension of the domain, $L$ is the number of ops in the forward computation graph, and $k$ is the derivative order. In previous works, the polynomial scaling in $d$ was addressed by amortizing the computation over the optimization process via randomization. Separately, the exponential scaling in $k$ for univariate functions ($d=1$) was addressed with high-order auto-differentiation (AD). In this work, we show how to efficiently perform arbitrary contraction of the derivative tensor of arbitrary order for multivariate functions, by properly constructing the input tangents to univariate high-order AD, which can be used to efficiently randomize any differential operator. When applied to Physics-Informed Neural Networks (PINNs), our method provides >1000$\times$ speed-up and >30$\times$ memory reduction over randomization with first-order AD, and we can now solve 1-million-dimensional PDEs in 8 minutes on a single NVIDIA A100 GPU. This work opens the possibility of using high-order differential operators in large-scale problems.
|
|
Best Paper
|
Oral
[ West Exhibition Hall C, B3 ] 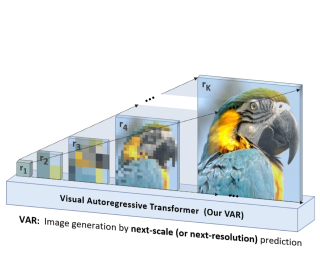
Abstract
We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine "next-scale prediction" or "next-resolution prediction", diverging from the standard raster-scan "next-token prediction". This simple, intuitive methodology allows autoregressive (AR) transformers to learn visual distributions fast and generalize well: VAR, for the first time, makes GPT-style AR models surpass diffusion transformers in image generation. On ImageNet 256x256 benchmark, VAR significantly improve AR baseline by improving Frechet inception distance (FID) from 18.65 to 1.73, inception score (IS) from 80.4 to 350.2, with around 20x faster inference speed. It is also empirically verified that VAR outperforms the Diffusion Transformer (DiT) in multiple dimensions including image quality, inference speed, data efficiency, and scalability. Scaling up VAR models exhibits clear power-law scaling laws similar to those observed in LLMs, with linear correlation coefficients near -0.998 as solid evidence. VAR further showcases zero-shot generalization ability in downstream tasks including image in-painting, out-painting, and editing. These results suggest VAR has initially emulated the two important properties of LLMs: Scaling Laws and zero-shot task generalization. We have released all models and codes to promote the exploration of AR/VAR models for visual generation and unified learning.
|
|
Best Paper Runner-up
|
Oral
[ West Exhibition Hall C, B3 ] 
Abstract
Previous language model pre-training methods have uniformly applied a next-token prediction loss to all training tokens. Challenging this norm, we posit that ''Not all tokens in a corpus are equally important for language model training''. Our initial analysis examines token-level training dynamics of language model, revealing distinct loss patterns for different tokens. Leveraging these insights, we introduce a new language model called Rho-1. Unlike traditional LMs that learn to predict every next token in a corpus, Rho-1 employs Selective Language Modeling (SLM), which selectively trains on useful tokens that aligned with the desired distribution. This approach involves scoring training tokens using a reference model, and then training the language model with a focused loss on tokens with higher scores. When continual continual pretraining on 15B OpenWebMath corpus, Rho-1 yields an absolute improvement in few-shot accuracy of up to 30% in 9 math tasks. After fine-tuning, Rho-1-1B and 7B achieved state-of-the-art results of 40.6% and 51.8% on MATH dataset, respectively - matching DeepSeekMath with only 3% of the pretraining tokens. Furthermore, when continual pretraining on 80B general tokens, Rho-1 achieves 6.8% average enhancement across 15 diverse tasks, increasing both data efficiency and performance of the language model pre-training.
|
|
Datasets and Benchmarks Best Paper
|
Oral
[ West Exhibition Hall C, B3 ] Abstract
Human feedback is central to the alignment of Large Language Models (LLMs). However, open questions remain about the methods (how), domains (where), people (who) and objectives (to what end) of feedback processes. To navigate these questions, we introduce PRISM, a new dataset which maps the sociodemographics and stated preferences of 1,500 diverse participants from 75 countries, to their contextual preferences and fine-grained feedback in 8,011 live conversations with 21 LLMs. With PRISM, we contribute (i) wider geographic and demographic participation in feedback; (ii) census-representative samples for two countries (UK, US); and (iii) individualised ratings that link to detailed participant profiles, permitting personalisation and attribution of sample artefacts. We target subjective and multicultural perspectives on value-laden and controversial issues, where we expect interpersonal and cross-cultural disagreement. We use PRISM in three case studies to demonstrate the need for careful consideration of which humans provide alignment data.
|
Successful Page Load