Large Spatial Model: End-to-end Unposed Images to Semantic 3D
{kind=link}
Abstract
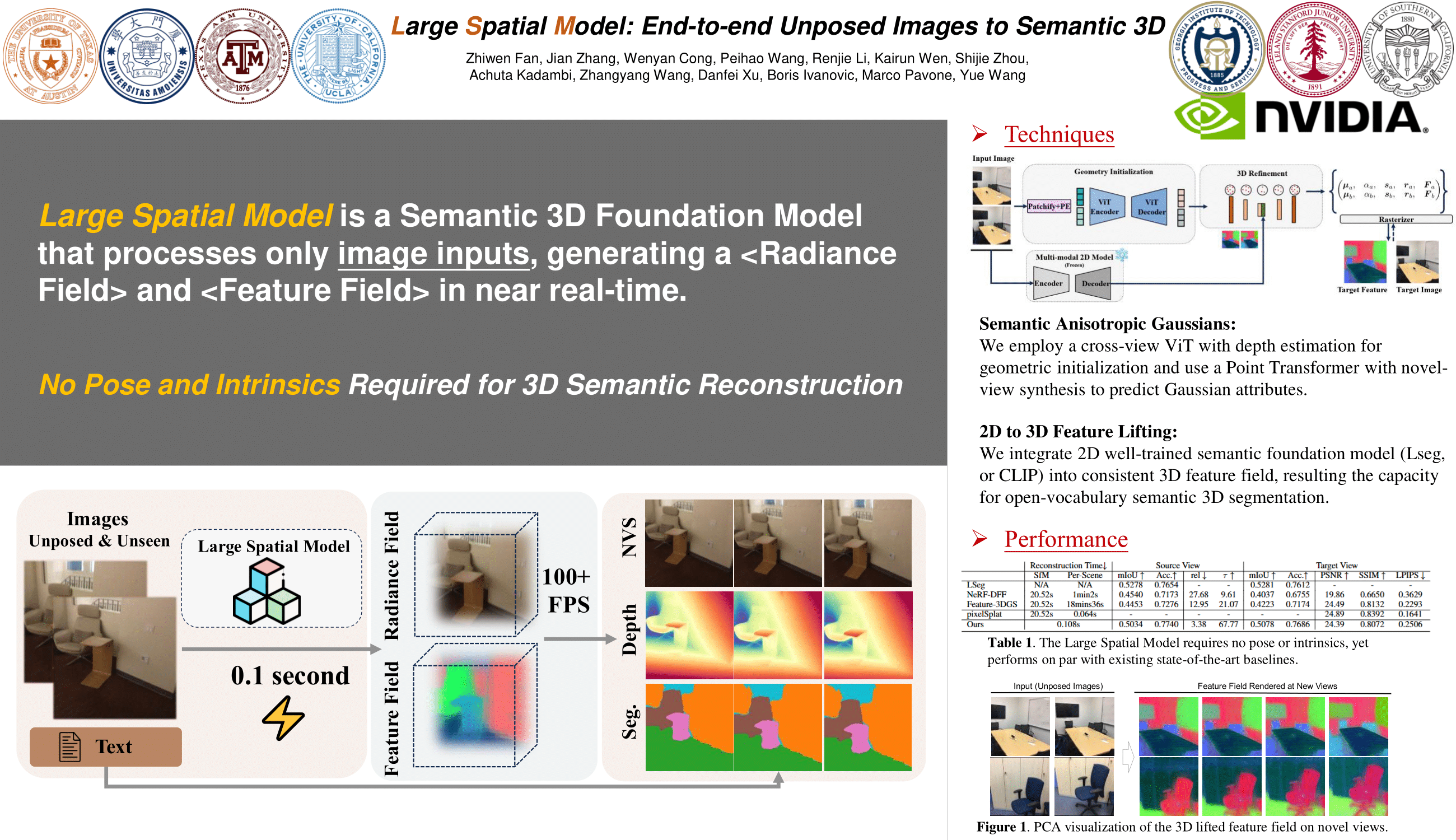
Reconstructing and understanding 3D structures from a limited number of images is a classical problem in computer vision. Traditional approaches typically decompose this task into multiple subtasks, involving several stages of complex mappings between different data representations. For example, dense reconstruction using Structure-from-Motion (SfM) requires transforming images into key points, optimizing camera parameters, and estimating structures. Following this, accurate sparse reconstructions are necessary for further dense modeling, which is then input into task-specific neural networks. This multi-stage paradigm leads to significant processing times and engineering complexity.In this work, we introduce the Large Spatial Model (LSM), which directly processes unposed RGB images into semantic radiance fields. LSM simultaneously estimates geometry, appearance, and semantics in a single feed-forward pass and can synthesize versatile label maps by interacting through language at novel views. Built on a general Transformer-based framework, LSM predicts global geometry via pixel-aligned point maps. To improve spatial attribute regression, we adopt local context aggregation with multi-scale fusion, enhancing the accuracy of fine local details. To address the scarcity of labeled 3D semantic data and enable natural language-driven scene manipulation, we incorporate a pre-trained 2D language-based segmentation model into a 3D-consistent semantic feature field. An efficient decoder parameterizes a set of semantic anisotropic Gaussians, allowing supervised end-to-end learning. Comprehensive experiments on various tasks demonstrate that LSM unifies multiple 3D vision tasks directly from unposed images, achieving real-time semantic 3D reconstruction for the first time.