Multi-Reward Best Policy Identification
Alessio Russo ⋅ Filippo Vannella
2024 Poster
{kind=link}
Abstract
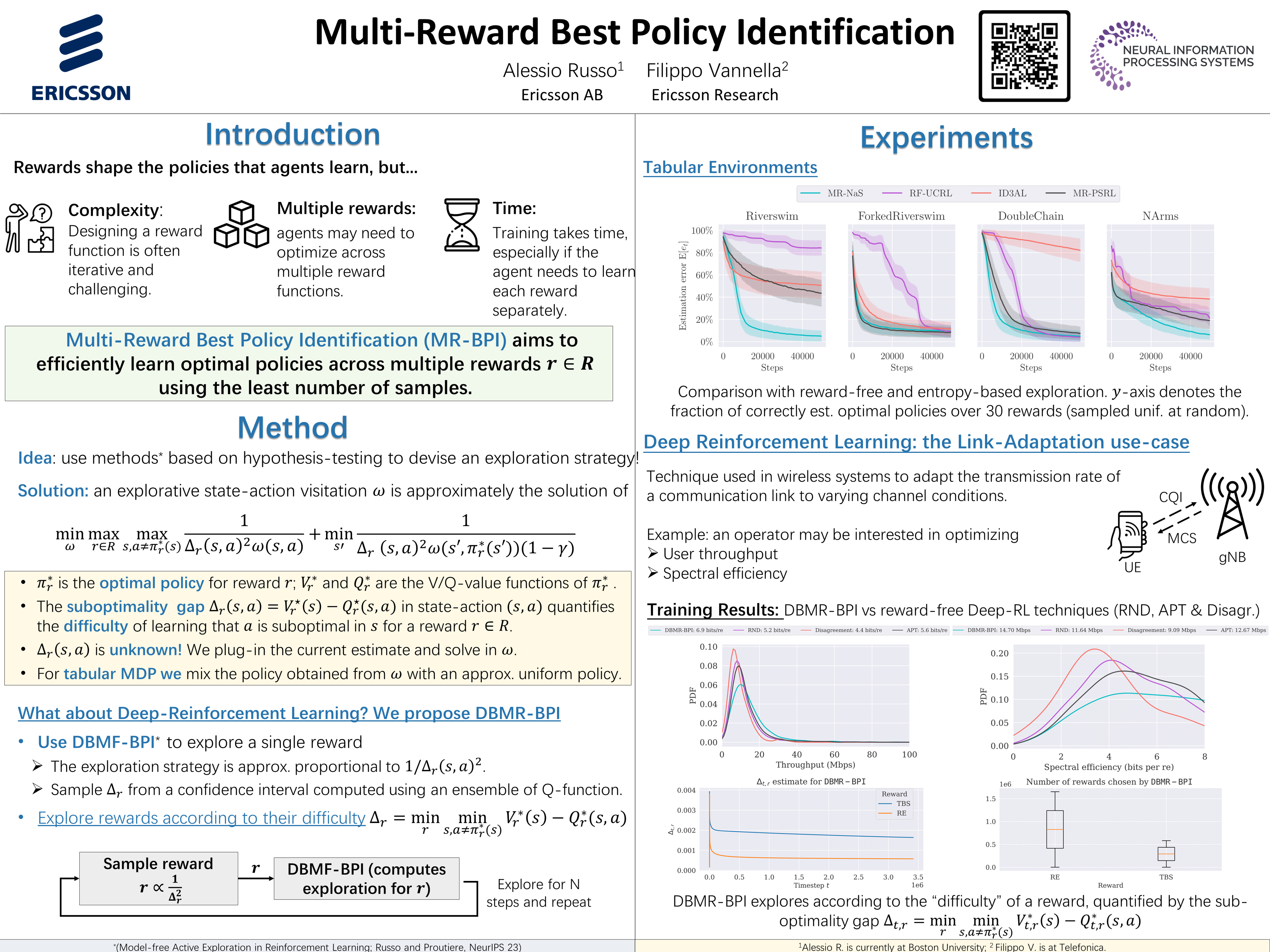
Rewards are a critical aspect of formulating Reinforcement Learning (RL) problems; often, one may be interested in testing multiple reward functions, or the problem may naturally involve multiple rewards. In this study, we investigate the _Multi-Reward Best Policy Identification_ (MR-BPI) problem, where the goal is to determine the best policy for all rewards in a given set $\mathcal{R}$ with minimal sample complexity and a prescribed confidence level. We derive a fundamental instance-specific lower bound on the sample complexity required by any Probably Correct (PC) algorithm in this setting. This bound guides the design of an optimal exploration policy attaining minimal sample complexity. However, this lower bound involves solving a hard non-convex optimization problem. We address this challenge by devising a convex approximation, enabling the design of sample-efficient algorithms. We propose MR-NaS, a PC algorithm with competitive performance on hard-exploration tabular environments. Extending this approach to Deep RL (DRL), we also introduce DBMR-BPI, an efficient algorithm for model-free exploration in multi-reward settings.
Video
Chat is not available.
Successful Page Load