DropBP: Accelerating Fine-Tuning of Large Language Models by Dropping Backward Propagation
Sunghyeon Woo ⋅ Baeseong Park ⋅ Byeongwook Kim ⋅ Minjung Jo ⋅ Se Jung Kwon ⋅ Dongsuk Jeon ⋅ Dongsoo Lee
2024 Poster
{kind=link}
Abstract
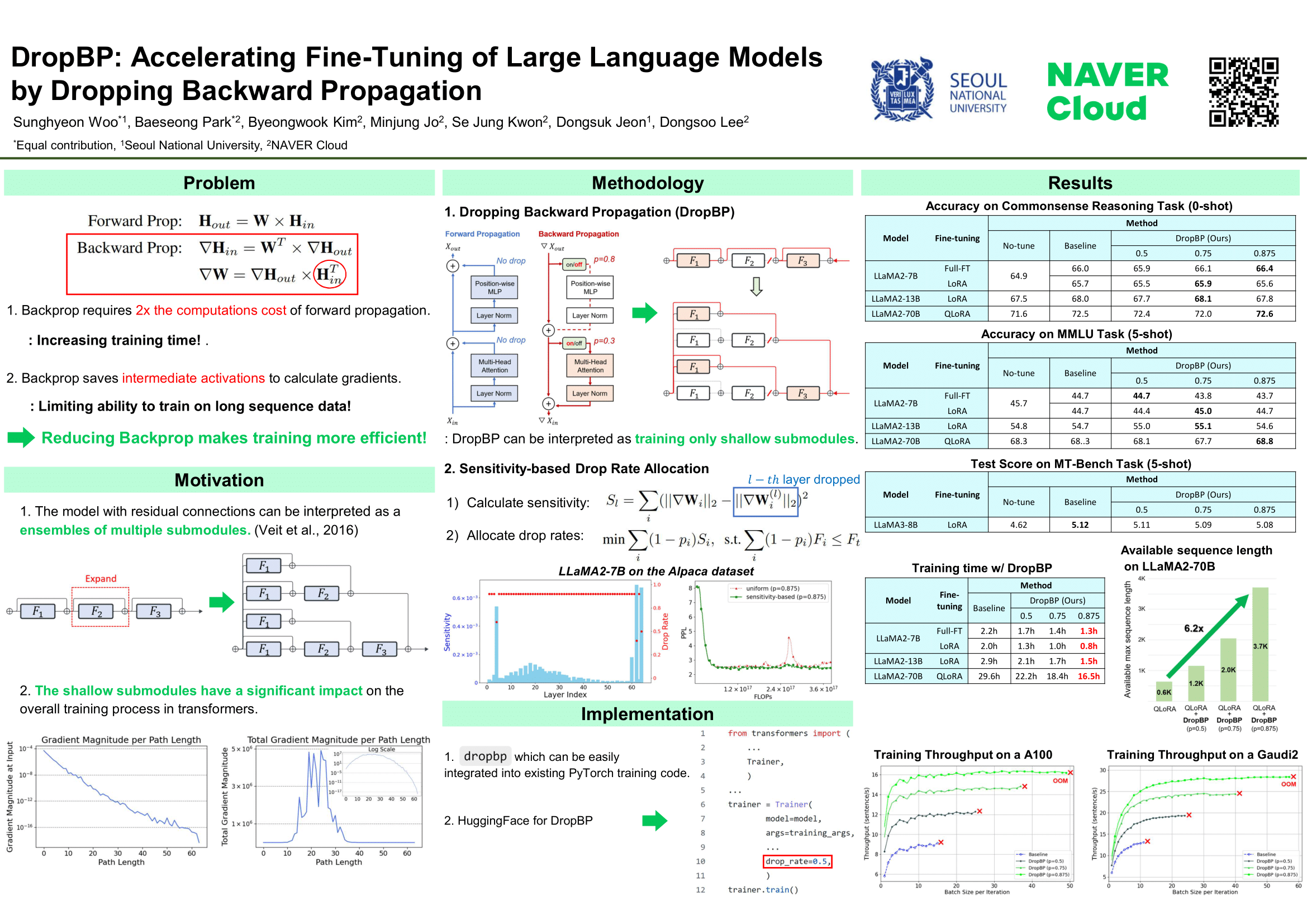
Large language models (LLMs) have achieved significant success across various domains. However, training these LLMs typically involves substantial memory and computational costs during both forward and backward propagation. While parameter-efficient fine-tuning (PEFT) considerably reduces the training memory associated with parameters, it does not address the significant computational costs and activation memory. In this paper, we propose Dropping Backward Propagation (DropBP), a novel approach designed to reduce computational costs and activation memory while maintaining accuracy. DropBP randomly drops layers during backward propagation, which is essentially equivalent to training shallow submodules generated by undropped layers and residual connections. Additionally, DropBP calculates the sensitivity of each layer to assign an appropriate drop rate, thereby stabilizing the training process. DropBP is not only applicable to full fine-tuning but can also be orthogonally integrated with all types of PEFT by dropping layers during backward propagation. Specifically, DropBP can reduce training time by 44% with comparable accuracy to the baseline, accelerate convergence to the same perplexity by 1.5$\times$, and enable training with a sequence length 6.2$\times$ larger on a single NVIDIA-A100 GPU. Furthermore, our DropBP enabled a throughput increase of 79% on a NVIDIA A100 GPU and 117% on an Intel Gaudi2 HPU. The code is available at [https://github.com/WooSunghyeon/dropbp](https://github.com/WooSunghyeon/dropbp).
Video
Chat is not available.
Successful Page Load